Large Result Offloading: Demand-Driven Context Management for Tool-Augmented Language Models
Abstract. Tool-augmented language models face a structural mismatch: retrieval operations return result sets whose token cost far exceeds what the model consumes downstream. We formalize and empirically evaluate Large Result Offloading (LRO), a token-aware materialization strategy that writes large tool outputs to structured files and returns a compact descriptor (metadata, schema, and extraction queries) in place of the full payload. We evaluate LRO across 126 evaluation runs spanning two models (Claude Haiku 4.5, GPT-5-mini), three corpus scales (50, 200, 500 records), two task types (ID lookup and multi-field filtering), and 21 experimental conditions. LRO agents achieve 73—100% task accuracy on whole-corpus ID lookup operations where the inline baseline collapses to 0—7%, a result that holds even when the inline agent is given a persistent Python execution environment (0% accuracy). Token savings of 40—62% at scale are a secondary benefit; the primary contribution is enabling whole-corpus operations that are architecturally fragile under naive inline pagination. A descriptor ablation study reveals that agents ignore rich metadata under natural behavior: a bare file pointer performs as well as a full descriptor on ID lookup tasks. A second ablation on multi-field filter tasks confirms this pattern, while revealing that filter tasks are harder by a wider margin (12.9% accuracy across all descriptor configurations); future descriptor designs should target task complexity rather than metadata richness. Recipe utility is model-dependent: capable models derive no benefit from extraction templates, while weaker models show +13—20 percentage point improvement in goal achievement. These findings reframe LRO’s value proposition: the primary contribution is task enablement, not cost reduction. Task complexity is the next frontier for descriptor design.
Introduction
Section titled “Introduction”Large language models now orchestrate multi-step workflows through tool invocations. Modern agent frameworks connect models to databases, APIs, file systems, and memory stores via protocols like MCP, enabling retrieval and action across dozens of external systems within a single task. Each tool invocation returns its output into the model’s context window, a shared resource that must accommodate tool results, instructions, conversation history, and the model’s own reasoning. As agents scale in tool count and task complexity, tool output volume routinely exceeds what the context window can absorb without degrading performance.
Recent work has formalized this as the context window overflow problem. Zhang et al. [1] demonstrate that as agentic tasks scale in complexity and horizon length, accumulated tool observations frequently exceed the model’s effective context capacity, leading to degraded task completion rates and increased error propagation. Their analysis shows that overflow is not merely a theoretical concern but a practical bottleneck in production agent deployments.
Memory retrieval systems are the acute case. A single recall_memories invocation returning 200 memories at full detail produces 40,000+ tokens, consuming half a typical context window for raw data that the model will filter to a small subset. The MCP (Model Context Protocol) ecosystem amplifies this pressure: as Eckstein [17] observes, tool proliferation creates a combinatorial context burden where each additional tool contributes both schema overhead and result payloads.
The consequences fall into two categories that compound each other.
The cost problem is straightforward. Token cost scales linearly with context size. Injecting result tokens when the model consumes where wastes expenditure proportional to . Chen et al. [13] formalize this as the action registration cost problem in their EcoAct framework. But the economic cost goes beyond dollars per token: every token consumed by tool output is a token unavailable for reasoning, planning, and response generation. The JetBrains research team [6] shows that observation management (choosing what tool outputs to retain, mask, or summarize) impacts agent performance on software engineering tasks. The cost is paid twice: once in money and once in capability.
The reasoning degradation is harder to see but more damaging. Transformer-based models exhibit diminished attention fidelity over long sequences. Liu et al. [20] demonstrate the “lost in the middle” phenomenon: information buried in long contexts receives less attention. Kate et al. [21] measure this directly for tool-augmented systems, finding that function-calling accuracy degrades 7—91% as tool response length increases, with degradation onset well below typical context limits. Li et al. [9] draw parallels between this problem and buffer management in database systems. The implication is concrete: burying relevant information within a large payload of irrelevant tool results reduces the probability of correct downstream reasoning, and the model cannot detect what it missed, especially when relevant records are dispersed across a large payload.
A third failure mode emerges from our empirical evaluation and, to our knowledge, has not been documented in prior work: pagination-induced state loss. When inline delivery requires multiple paginated tool calls, the model must maintain a running tally across API turns. Our results (Section 6) show that models universally fail at this: counting operations that aggregate results across paginated responses achieve 0—7% accuracy regardless of model capability. The failure is architectural, not capability-based: each paginated response competes with prior responses for attention, and the model cannot reliably accumulate state across sequential tool invocations.
LRO addresses these failure modes by introducing an indirection layer between tool execution and context injection. Result content binds to model context only when the model requests specific subsets. This reframes the problem from “how do we fit more into context” to “how do we design the information contract between tools and agents so that context consumption is demand-driven rather than supply-driven.”
LRO instantiates this demand-driven pattern as a concrete specification for MCP-compatible memory servers. While prior systems have offloaded data (MemGPT [2], CodeAct sandboxes [12]) or compressed it (ACON [5], LLMLingua [7]), our contribution is threefold: a threshold-based offloading spec with structured descriptors, a systematic evaluation of the pagination failure mode, and an empirical analysis of descriptor utility.
The empirical evaluation in Section 6, conducted across 126 evaluation runs with two models, three corpus scales, and two task types, shows that LRO does not merely reduce cost. It enables whole-corpus operations that are architecturally fragile with naive pagination.
Key empirical findings (Section 6; 126 evaluation runs, 21 experimental conditions):
- Task enablement: LRO achieves 73—100% count accuracy on whole-corpus ID lookup operations where inline delivery collapses to 0—7% (Table 3, Figure 1). A CodeAct-style baseline providing a persistent Python execution environment alongside paginated data achieves 0% accuracy, confirming that the failure is architectural rather than tooling-limited (Table 3).
- Token savings: 40—62% reduction in API tokens at n 200; slight overhead at n=50 (Table 5, Figure 2).
- Descriptor paradox: A bare file pointer (95.6% accuracy) outperforms the full descriptor (84.4%) on ID lookup tasks. Agents ignore rich metadata under natural behavior (Table 7, Figure 4).
- Task-dependent descriptor utility: On multi-field filter tasks requiring namespace filtering, priority comparison, and content search, all descriptor configurations achieve 12.9% accuracy while inline delivery collapses to 0%. The descriptor paradox holds across task types, but filter tasks expose a harder problem: agents struggle with multi-criteria queries regardless of metadata richness (Table 11, Section 6.4).
- Model-dependent scaffolding: Extraction recipes provide no benefit for capable models but improve goal achievement by 13—20pp for weaker ones (Table 9, Figure 6).
Formal Definition
Section titled “Formal Definition”Large Result Offloading (LRO) is a token-aware result materialization strategy for tool-augmented language model systems. When a tool invocation produces a result set whose estimated token count exceeds a predefined budget threshold , the system:
- Materializes the complete result set to an out-of-band structured file in line-delimited JSON (JSONL) format.
- Returns an in-band compact descriptor comprising:
- (a) aggregate metadata summarizing (cardinality, token estimate, distribution statistics),
- (b) a schema definition enabling typed interpretation of each record in , and
- (c) a library of deterministic extraction queries that the agent can invoke selectively against .
The threshold function is:
where is a token estimation function and is a configurable global constant (default: 1,600 tokens). Token estimation follows a character-ratio heuristic: for Latin-script content, with model-specific tokenizers recommended for CJK or mixed-script corpora.
Related Work
Section titled “Related Work”LRO sits at the intersection of context management, agent memory systems, and tool-augmented LLM architectures. Two recent surveys frame the landscape. Huang et al. [22] organize 218 papers along three design dimensions (memory substrates, cognitive mechanisms, and memory subjects), identifying context explosion in long-horizon tasks as a central challenge. Zhang et al. [23] offer a complementary taxonomy distinguishing token-level, parametric, and latent memory forms, with their “working memory” category mapping directly to the context window resource that LRO manages. LRO addresses one facet of the challenge both surveys identify: the interface between retrieval output and agent consumption. We organize the related work by the primary strategy each employs and identify where LRO diverges.
Context Window Management as Virtual Memory
Section titled “Context Window Management as Virtual Memory”The most structurally similar prior work is MemGPT [2], which models the LLM context window as a virtual memory system with main memory (context window) and external storage (database/files). MemGPT introduces page-in/page-out operations that move information between these tiers based on agent needs, directly analogous to OS-level demand paging. LRO shares MemGPT’s foundational insight that the context window should be treated as a managed resource with explicit eviction and loading policies, but differs in its loading interface. Where MemGPT provides generic memory management primitives (core_memory_append, archival_memory_search), LRO provides result-specific extraction queries tailored to a particular tool output’s schema. The difference matters: MemGPT’s primitives require the agent to formulate its own retrieval strategy, while LRO’s descriptor includes pre-computed queries that encode domain knowledge about common access patterns.
The virtual memory analogy extends to the systems level. Kwon et al.’s PagedAttention [16] and Prabhu et al.’s vAttention [15] apply paging concepts to the KV-cache layer of transformer inference, managing GPU memory through block-level allocation and on-demand loading. While these operate at a different abstraction layer (inference engine memory rather than semantic context), they validate the broader principle that demand-driven loading outperforms eager allocation when the working set is smaller than the total addressable space.
Context Compression and Distillation
Section titled “Context Compression and Distillation”A large body of work addresses context overflow through compression: reducing the token footprint of information before or after it enters the context window.
Prompt compression. LLMLingua [7] and its successors apply token-level and sentence-level compression to prompts, achieving 2—20x compression ratios with acceptable fidelity loss on downstream tasks. Selective Context [8] uses self-information metrics to identify and prune low-information tokens. Both trade fidelity for space: the compressed representation is a lossy approximation of the original.
Agent observation compression. ACON [5] targets long-horizon agent tasks, applying different compression levels to different context components (history, observations, instructions). ACON uses configurable token thresholds (e.g., 4,096 tokens for history, 1,024 for observations) to trigger compression. LRO’s threshold mechanism resembles ACON’s but differs in a critical respect: ACON’s thresholds trigger lossy compression of accumulated context, while LRO’s threshold triggers lossless offloading of a single result set. The information is preserved in full; only the delivery mechanism changes.
Progressive context loading. Zujkowski [4] documents a practitioner pattern, progressive context loading, that reduces initial context consumption by 93% through staged information delivery. This approach shares LRO’s demand-driven philosophy but operates at the conversation management level rather than the tool response level.
LRO is not a compression technique. It preserves the complete result set at full fidelity in the materialized file, relocating it from the context window to an addressable store. The compact descriptor is a navigational index, not a lossy summary. A caveat: while the materialized data is lossless, the descriptor itself is a compressed representation (aggregate metadata, distribution statistics) that the agent uses to decide what to materialize. If the descriptor’s summary is misleading for a particular query, the agent may make a suboptimal materialization decision. The fidelity guarantee applies to records accessed through extraction queries, not to the agent’s reasoning about which records to access.
Decoupled Reasoning and Observation
Section titled “Decoupled Reasoning and Observation”ReWOO [11] demonstrates that reasoning and observation can be decoupled in agent pipelines. The planner generates a complete plan with placeholder variables for tool outputs, and a worker module executes tools and fills in the variables. This decoupling reduces context consumption because the planner does not need to see intermediate tool outputs during planning.
LRO applies a complementary form of decoupling: the tool executes and produces its full output, but binding that output to the agent’s reasoning context is deferred. Where ReWOO decouples planning from observation, LRO decouples tool execution from context injection. The agent receives a descriptor, reasons about the result set’s structure, and selectively binds specific subsets.
Code-Based Agent Actions
Section titled “Code-Based Agent Actions”CodeAct [12] demonstrates that agents operating through executable code actions, rather than constrained tool APIs, achieve superior performance on complex tasks. CodeAct agents can write Python code that processes data in a sandboxed environment, naturally enabling out-of-band data manipulation. LRO’s extraction query library (jq recipes) instantiates a similar principle in a more constrained form: rather than giving the agent a general-purpose programming environment, it provides a curated set of domain-specific queries that cover the most common access patterns for structured memory data.
MOSS [19] extends this pattern by enabling code-driven evolution of agent capabilities, including context management through programmatic interfaces. LRO’s query library is a specialized instance of MOSS’s code-driven context management, narrowed to the tool response layer.
Hierarchical and Agentic Retrieval
Section titled “Hierarchical and Agentic Retrieval”A-RAG [3] introduces hierarchical retrieval with specialized sub-agents for different retrieval modalities (keyword search, semantic search, chunk read). While A-RAG’s sub-agents provide generic retrieval interfaces, LRO provides result-specific extraction commands tailored to the structure of a particular tool’s output. A-RAG optimizes the retrieval phase; LRO optimizes the consumption phase after retrieval has completed.
Database Perspectives on LLM Resource Management
Section titled “Database Perspectives on LLM Resource Management”Li et al. [9] map database system concepts to LLM inference challenges (VLDB). Their analysis identifies buffer management, query optimization, and result set handling as areas where decades of database research apply to LLM system design. LRO directly instantiates their observation about result spooling: when a query produces a result set exceeding client buffer capacity, the system materializes to server-side storage and provides a cursor interface for demand-driven access. In LRO, the “cursor” is the extraction query library and the “client buffer” is the context window.
Oracle’s comparative analysis of file systems and databases for AI agent memory [10] further validates the file-based materialization approach, finding that structured file formats provide adequate performance for agent memory access patterns while offering superior compatibility with shell-based tool execution environments.
Positioning
Section titled “Positioning”LRO is a concrete instantiation and evaluation of result materialization in the MCP/memory context, building on several related lines of work:
- Systems that offload data (MemGPT [2], CodeAct sandboxes [12], file-based practitioner patterns [4]) but lack structured descriptors with typed schemas and pre-computed extraction queries.
- Systems that compress data (ACON [5], LLMLingua [7], Selective Context [8]) but sacrifice fidelity to reduce token footprint.
- Systems that hierarchically retrieve (A-RAG [3], MemGPT [2]) but do not formalize the descriptor-as-interface contract between tool output and agent consumption.
Two concurrent benchmarks, MemoryArena [25] (multi-session agent memory tasks averaging 40K+ tokens) and AgentLongBench [26] (controllable long-context evaluation via environment rollouts), show that context management is a bottleneck in production agent deployments. Both benchmarks evaluate retrieval quality; LRO addresses the delivery mechanism for results after retrieval completes.
The specific contribution is the formalization of the tool output as an interface boundary: the descriptor serves as a typed API between the retrieval subsystem and the reasoning subsystem. None of the above systems formalize this contract for tool outputs specifically. The descriptor is not a pointer to offloaded data; it is a navigational interface that encodes schema, metadata, and executable access patterns.
Architecture
Section titled “Architecture”Decision Flow
Section titled “Decision Flow”The LRO decision point occurs after operation completion but before response formatting:
: Return inline response (conventional path)
: Materialize to JSONL Return compact descriptor
The threshold is evaluated against the aggregate result set, not individual records. A collection of individually small records whose aggregate exceeds triggers offloading; a single large record below is returned inline.
This per-result threshold evaluation distinguishes LRO from systems like ACON [5], where thresholds are evaluated against accumulated context size across an entire agent trajectory. LRO’s per-result granularity enables more precise control: a small result set is returned inline with zero overhead, while only large result sets incur the materialization cost.
Materialization Format
Section titled “Materialization Format”Offloaded results are written as line-delimited JSON (JSONL), chosen for the following properties:
JSONL’s key properties (line-oriented streaming, native jq/grep compatibility, append-friendly, partial read support) are detailed in Appendix A. The choice of JSONL over JSON arrays reflects the CodeAct [12] insight that agent effectiveness improves when the data format aligns with the agent’s available execution tools. For agents operating in shell environments, the dominant modality for tool-augmented coding assistants, JSONL’s compatibility with Unix pipeline idioms (tail -n +2 | jq...) minimizes the cognitive and syntactic overhead of data access.
The file structure comprises:
- Line 0 (Header): Metadata record containing operation identifier, result cardinality, schema version, timestamp, estimated token count, and detail level.
- Lines 1..n (Records): One complete structured object per line, serialized at the requested detail level with all domain-relevant fields.
File naming follows the convention {output_dir}/lro-{operation}-{ulid}.jsonl, where the ULID provides both collision resistance and temporal ordering.
Compact Descriptor
Section titled “Compact Descriptor”The in-band descriptor (OffloadResponse) contains:
- Summary statistics: Result cardinality, estimated tokens saved, operation type, top-k namespace distribution, and score range.
- File reference: Absolute path to the materialized JSONL file.
- Line schema: JSON Schema definition for each record line, enabling the agent to interpret field structure without external schema lookup.
- Extraction query library: A set of 10 standard
jqrecipes covering common access patterns (see table below). - Guidance prompt: A natural language instruction block informing the agent of the offloaded state and suggesting consumption strategies (see Appendix C for a representative example). The guidance prompt orients the agent to the offloaded state and suggests starting points, using advisory tone (“Use … to extract”) rather than imperative (“You must …”) to allow agents without shell access to skip extraction gracefully.
Representative extraction queries from the library cover enumeration, filtering, search, aggregation, and ranking patterns (see Appendix B for the full recipe table). All recipes use tail -n +2 to skip the header line and are composable via Unix pipeline chaining.
Pre-computed extraction queries distinguish LRO’s descriptor from simpler file-pointer approaches. The JetBrains research team [6] shows that observation management strategies (masking versus LLM-based summarization of prior tool outputs) affect agent task completion. Their study addresses replacement strategies for prior observations rather than structured access to new tool outputs, but the finding supports a broader principle: how agents interface with tool output data matters as much as what data is available. The query library encodes domain knowledge about common structured memory access patterns, reducing the agent’s planning burden.
Our empirical results (Section 6.3) complicate this picture: agents largely ignore the query library under natural behavior, defaulting to their own jq and grep commands regardless of descriptor richness. The library’s practical value is conditional on explicit prompting or on task types that require the specific queries it provides.
Alternative Extraction Interfaces
Section titled “Alternative Extraction Interfaces”The reference extraction library uses jq and Unix pipelines, reflecting the shell-capable environments where LRO is most applicable (Section 5.3). The descriptor pattern is interface-agnostic: the same compact descriptor could serve HTTP range endpoints, tool-based pagination via read_offloaded(file, offset, limit, filter), or language-native bindings (Python, TypeScript). Each alternative trades generality against expressiveness; the schema definition and summary metadata retain their value across all interfaces. Alternative interfaces including local proxy materialization and native MCP extraction tools are discussed in Appendix E.
Lifecycle Management
Section titled “Lifecycle Management”Materialized files are ephemeral. Each file carries a time-to-live (TTL, default: 3,600 seconds) and a creation timestamp. A registered custodial task (offload_cleanup) periodically scans the output directory and deletes files whose TTL has elapsed, emitting observability events for audit purposes.
If materialization fails (e.g., disk full, permission error), the system falls back to an inline truncated response rather than failing the operation. LRO is an optimization; the underlying operation’s success must not depend on it. This degradation path ensures LRO introduces no new failure modes, consistent with IBM’s analysis of MCP tool integration requirements [18].
Theoretical Analysis
Section titled “Theoretical Analysis”Context Window Savings
Section titled “Context Window Savings”For a result set of n memories at average token cost t per memory, the inline approach consumes tokens. The LRO descriptor consumes a fixed overhead (approximately 800 tokens for the summary, schema, and recipe library) plus for any subsequent selective extraction of records.
The savings ratio is:
For a representative memory recall where the agent consumes 2% of returned records (, , , ):
This yields approximately 96% context window savings for the stated parameters. The savings depend entirely on the access ratio , the fraction of returned records the agent actually consumes. Table 1 shows savings across representative result set sizes, using tokens/record and tokens descriptor overhead.
Table 1. Context window savings by access ratio and result set size.
| 0.01 | 88.7% | 93.8% | 96.9% | 98.0% |
| 0.02 | 87.7% | 92.8% | 95.9% | 97.0% |
| 0.05 | 84.7% | 89.8% | 92.9% | 94.0% |
| 0.10 | 79.7% | 84.8% | 87.9% | 89.0% |
| 0.25 | 64.7% | 69.8% | 72.9% | 74.0% |
| 0.50 | 39.7% | 44.8% | 47.9% | 49.0% |
The breakeven point, where LRO’s descriptor overhead exceeds the savings from not injecting results inline, occurs when approaches . For , breakeven is at (consuming 45 of 50 records). The default threshold = 1,600 tokens (approximately 10 records at ) avoids the small-n regime where breakeven is reached quickly.
This analysis assumes homogeneous record sizes ( tokens, the empirical mean for full-detail memory records) and a fixed descriptor overhead ( tokens for summary, schema, and 10 standard recipes). In practice, varies by record content and detail level, and scales with schema complexity and recipe count. The analysis is illustrative for the memory-recall use case; heterogeneous record sizes or multi-tool pipelines would require per-invocation estimation.
Comparison with Compression Approaches
Section titled “Comparison with Compression Approaches”Unlike lossy compression techniques (LLMLingua [7], ACON [5]), LRO preserves complete result fidelity. The savings come not from information loss but from information deferral. This property is critical for memory systems where metadata fields (confidence scores, provenance chains, entity references) carry semantic weight that lossy compression may discard.
| Approach | Fidelity | Savings | Mechanism |
|---|---|---|---|
| LLMLingua [7] | Lossy | 2—20x | Token-level prompt compression |
| ACON [5] | Lossy | Variable | Adaptive observation compression |
| Selective Context [8] | Lossy | 2—5x | Self-information pruning |
| Progressive Loading [4] | Lossless | ~93% | Staged conversation delivery |
| LRO | Lossless* | 40—62%† | Result materialization + guided extraction |
*Lossless with respect to materialized records accessed through extraction queries. The compact descriptor is a summary representation.
†Empirically measured savings at n 200 across two models (Section 6.2). Theoretical savings of ~96% assume optimal access ratio k/n = 0.02.
Deployment Applicability
Section titled “Deployment Applicability”LRO’s applicability is bounded by the intersection of two client capabilities: filesystem access and shell execution. Full LRO (descriptor + extraction queries) requires both; environments without filesystem access receive metadata-only descriptors. A local proxy can bridge remote MCP deployments by materializing JSONL files on the client’s filesystem (see Appendix D for the full deployment matrix).
Determinism and Auditability
Section titled “Determinism and Auditability”The extraction query library is fully deterministic: given a fixed materialized file and a query , the output is invariant across executions. This determinism, inherited from jq’s functional evaluation model, enables reproducible debugging of agent-tool interactions, audit trails linking agent decisions to specific data subsets, and regression testing of agent behavior against fixed result sets.
Most compression-based approaches do not share this determinism property. MemGPT-style [2] systems introduce a different source of non-determinism: the agent’s memory management decisions create path-dependent access patterns that vary across executions even for identical inputs.
Latency Overhead
Section titled “Latency Overhead”LRO introduces latency from file materialization and shell invocation. Measured file-write overhead is 23.9ms (E1, median across all LRO runs). Shell startup for a jq or grep command adds 50—100ms depending on the host. For interactive agent tasks where API round-trips are 500—2000ms, this overhead is negligible. For high-QPS batch inference pipelines, the cumulative shell-startup cost may warrant the native MCP extraction tool alternative (Appendix E), which eliminates shell overhead at the cost of implementation complexity. At small corpus scales (n=50), LRO’s fixed overhead can exceed the token savings (Table 5, Haiku 1.28x overhead), making it a net regression for corpora below the offload threshold.
Empirical Evaluation
Section titled “Empirical Evaluation”We evaluate LRO through four experiments testing specific claims about its utility, measured across two language models (Anthropic Claude Haiku 4.5, OpenAI GPT-5-mini), three corpus scales (50, 200, 500 structured memory records), and 21 experimental conditions. All experiments use deterministic mock tools and pre-generated JSONL files for reproducibility; no live MCP server is required at evaluation time.
Experimental Framework
Section titled “Experimental Framework”Task design. Experiments E1—E3 use a standardized ID lookup task. Each task presents the agent with 12 UUIDs (8 that exist in the corpus, 4 that do not) and asks: “Determine how many of these IDs exist in the memory store.” The correct answer is always 8. This design has a single objectively correct answer, requires actual corpus navigation (the agent cannot guess), scales cleanly across corpus sizes, and sharply differentiates delivery mechanisms: an LRO agent can solve it in 1—2 tool calls via grep, while an inline agent must paginate through 5—10 pages of results.
Experiment E4 introduces a second task type, aggregate filtering, to test whether descriptor utility varies with task complexity. Each aggregate filter task asks: “How many memories in namespace X have priority Y and mention product Z in their content?” Correct answers require conjunction of three criteria (exact namespace match, ordinal priority comparison, and case-insensitive content search), a composition that a single grep cannot express but a jq pipeline with schema awareness can. Ground truth counts range from 3 to 50 matching records per task.
Evaluation framework. We use Inspect AI [24] for all evaluations, with 15 tasks per condition, a 20-turn message limit per task, and model-specific API configurations. The primary metric is count accuracy: a binary score of 1.0 if the agent reports exactly 8, 0.0 otherwise. Token usage is measured as total_tokens from the model’s usage reporting, aggregated across all API calls within a sample.
Delivery strategies. Five strategies implement different data delivery mechanisms:
| Strategy | Data Delivery | Agent Tools |
|---|---|---|
| LRO | Compact descriptor + JSONL file on disk | list_memories, bash, file read tools |
| Inline | Paginated JSON arrays (5 records/page) | list_memories with pagination |
| Inline+Code | Paginated JSON arrays + persistent Python environment | list_memories with pagination, python_exec |
| Summary | Abbreviated records (id + title only), paginated (10/page) | list_memories with pagination |
| Truncation | Descriptor + file on disk, no shell | File read tools only (no bash) |
The Inline+Code strategy provides a stronger baseline motivated by CodeAct [12]: the agent receives paginated data (identical to Inline) but also has access to a python_exec tool that maintains a persistent namespace across invocations. The agent can accumulate results programmatically (e.g., results.extend(page_data)) rather than relying on in-context state tracking. This tests whether the inline failure mode is a tooling limitation or an architectural one.
Conditions. The 21 experimental conditions span four experiments: E1 (5 delivery strategies), E2 natural (5 descriptor ablation conditions, C1—C5), E2 guided (4 guided prompting variants, C1g—C4g), E3 (2 recipe conditions), and E4 (5 descriptor conditions on filter tasks). Each condition is evaluated at 3 scales x 2 models, yielding 126 evaluation runs.
Reproducibility. Task generation uses seed=42. All corpora are pre-generated and frozen. Mock tools return deterministic responses for each condition. The benchmark harness, task suites, and evaluation scripts are open-source.
Experiment 1: LRO Effectiveness
Section titled “Experiment 1: LRO Effectiveness”Claim under test: LRO enables LLMs to perform whole-corpus operations that are unreliable via naive inline pagination, while reducing token consumption. This claim holds even when the inline agent is given a persistent code execution environment.
Design: 5 strategies x 3 scales x 2 models x 15 tasks = 450 individual task evaluations.
Results:
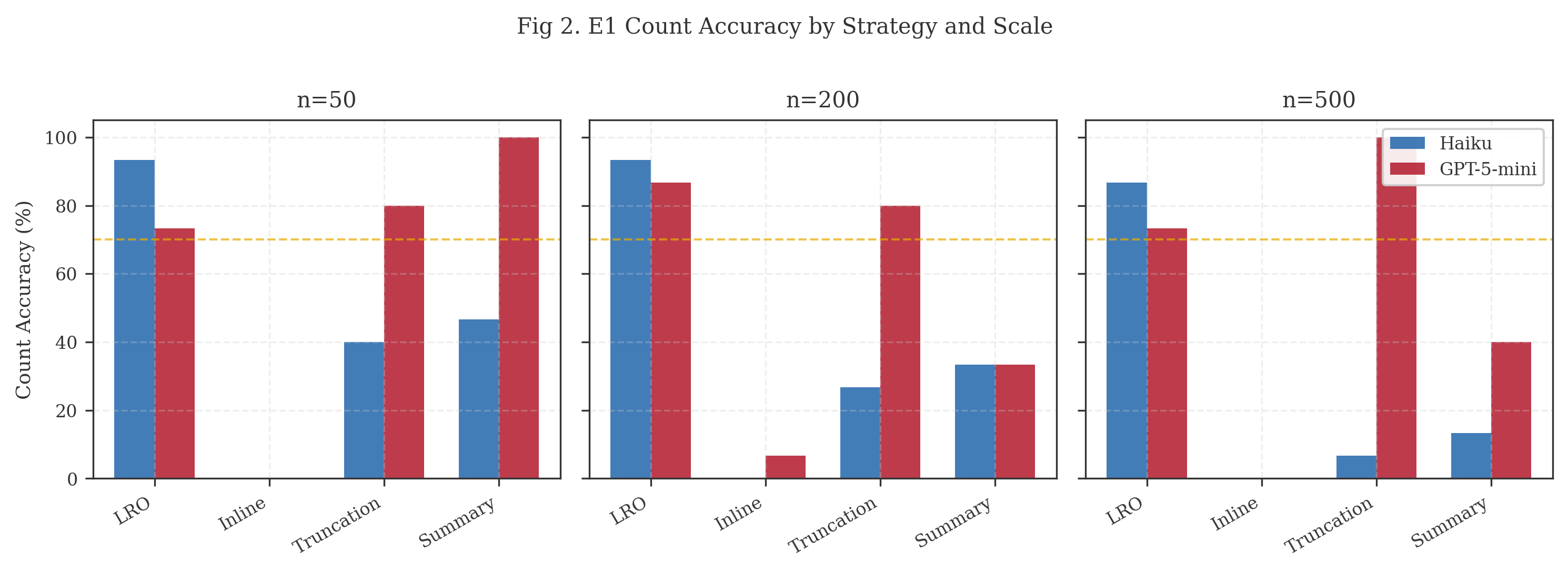
Table 3. E1 count accuracy (%) by strategy, scale, and model.
| Strategy | n=50 | n=200 | n=500 | |||
|---|---|---|---|---|---|---|
| Haiku | GPT-5-mini | Haiku | GPT-5-mini | Haiku | GPT-5-mini | |
| LRO | 93.3 | 73.3 | 93.3 | 86.7 | 86.7 | 73.3 |
| Inline | 0.0 | 0.0 | 0.0 | 6.7 | 0.0 | 0.0 |
| Inline+Code | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Summary | 46.7 | 100.0 | 33.3 | 33.3 | 13.3 | 40.0 |
| Truncation | 40.0 | 80.0 | 26.7 | 80.0 | 6.7 | 100.0 |
Table 4. E1 API tokens (thousands) by strategy, scale, and model.
| Strategy | n=50 | n=200 | n=500 | |||
|---|---|---|---|---|---|---|
| Haiku | GPT-5-mini | Haiku | GPT-5-mini | Haiku | GPT-5-mini | |
| LRO | 188 | 350 | 171 | 197 | 147 | 269 |
| Inline | 147 | 1,105 | 301 | 474 | 390 | 659 |
| Inline+Code | 198 | 1,717 | 289 | 512 | 415 | 724 |
| Summary | 83 | 67 | 206 | 233 | 315 | 474 |
| Truncation | 662 | 507 | 245 | 150 | 233 | 158 |
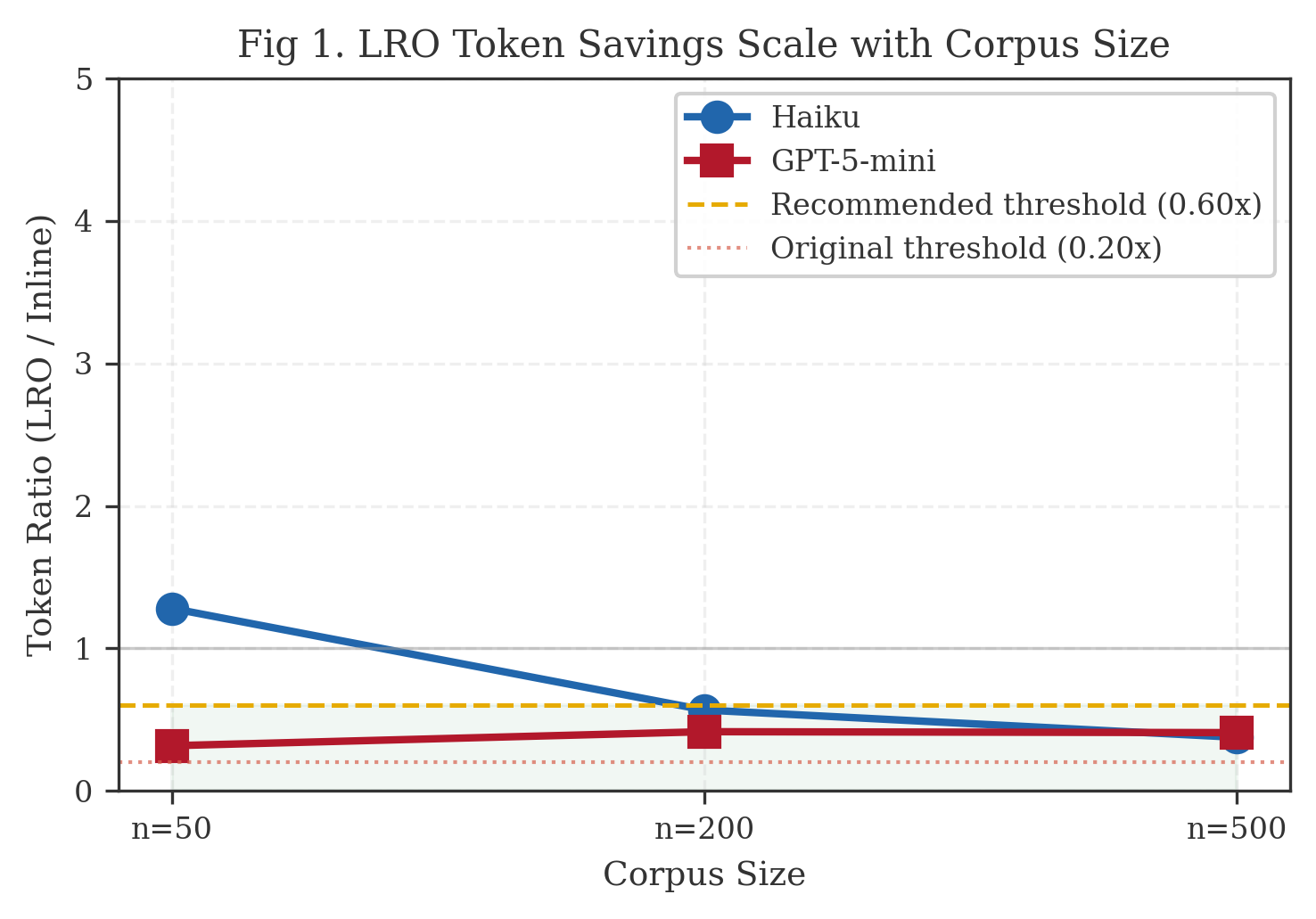
Table 5. E1 LRO/Inline token ratio by scale.
| Scale | Haiku | GPT-5-mini | Haiku savings | GPT-5-mini savings |
|---|---|---|---|---|
| n=50 | 1.28x | 0.32x | -28% overhead | 68% |
| n=200 | 0.57x | 0.42x | 43% | 58% |
| n=500 | 0.38x | 0.41x | 62% | 59% |
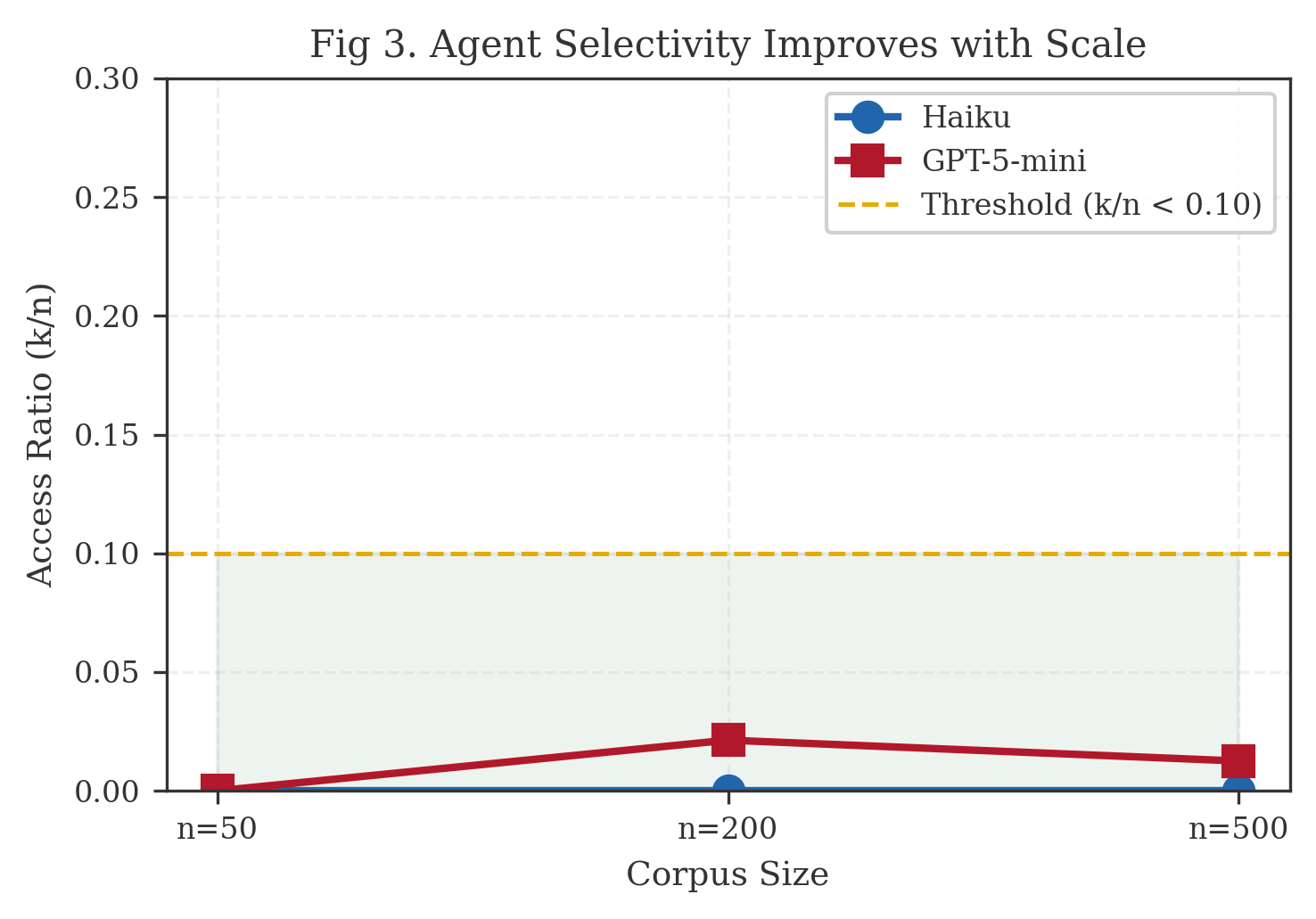
Access ratio: LRO agents read 0—2% of offloaded records ( = 0.000—0.021), well below the 10% threshold. File-write overhead was 23.9ms, negligible relative to API latency.
Analysis. The headline finding is not that LRO saves tokens but that LRO enables tasks inline delivery cannot complete. Inline count accuracy is 0—6.7% across all scales and models. The agent cannot reliably track running counts across paginated responses.
The Inline+Code strategy tests whether this failure is a tooling limitation. By providing a persistent Python execution environment alongside paginated data, we give the agent the ability to accumulate results programmatically across pages --- the approach advocated by CodeAct [12] for complex data processing. The result is unambiguous: Inline+Code achieves 0% accuracy across all six scale-model combinations, consuming 30—55% more tokens than standard Inline in the process. The agent attempts to use python_exec for accumulation but still loses state coherence across paginated tool responses. This confirms that the failure is architectural, not capability-based or tooling-limited: the context window cannot serve as a reliable accumulator regardless of what computational tools are available.
LRO achieves 73—93% accuracy by giving the agent a file on disk and shell tools. A single grep -c or jq command extracts the answer from the complete dataset without pagination. The key architectural difference is that LRO collapses the multi-turn pagination sequence into a single materialized artifact, eliminating the state-tracking burden entirely.
Token savings at n >= 200 range from 40—62%, with the ratio improving as corpus size grows. At n=50, LRO introduces a slight overhead for Haiku (1.28x) because the fixed cost of file setup and shell invocation exceeds the savings from not paginating a small dataset. This overhead disappears at larger scales.
Summary and truncation show inconsistent performance with high cross-model variance (e.g., summary achieves 100% for GPT-5-mini at n=50 but 13% for Haiku at n=500). Neither provides reliable accuracy across conditions.
Experiment 2: Descriptor Ablation
Section titled “Experiment 2: Descriptor Ablation”Claim under test: The descriptor’s components (schema, extraction recipes, guidance) contribute to LRO quality. Removing components should degrade performance.
Design: The ablation is structural: descriptor fields are removed from the OffloadResponse before the agent receives it. The agent cannot see removed fields. Five conditions:
| Condition | Schema | Recipes | Guidance | Description |
|---|---|---|---|---|
| C1 (Full LRO) | Yes | Yes | Yes | Complete descriptor |
| C2 (No Recipes) | Yes | No | Yes | Recipes removed |
| C3 (No Schema) | No | Yes | Yes | Schema removed |
| C4 (Bare Pointer) | No | No | No | File path only |
| C5 (Full Inline) | N/A | N/A | N/A | No offloading |
All LRO conditions (C1—C4) receive identical system prompts; only the descriptor content varies. C5 receives no LRO instruction.
Results:
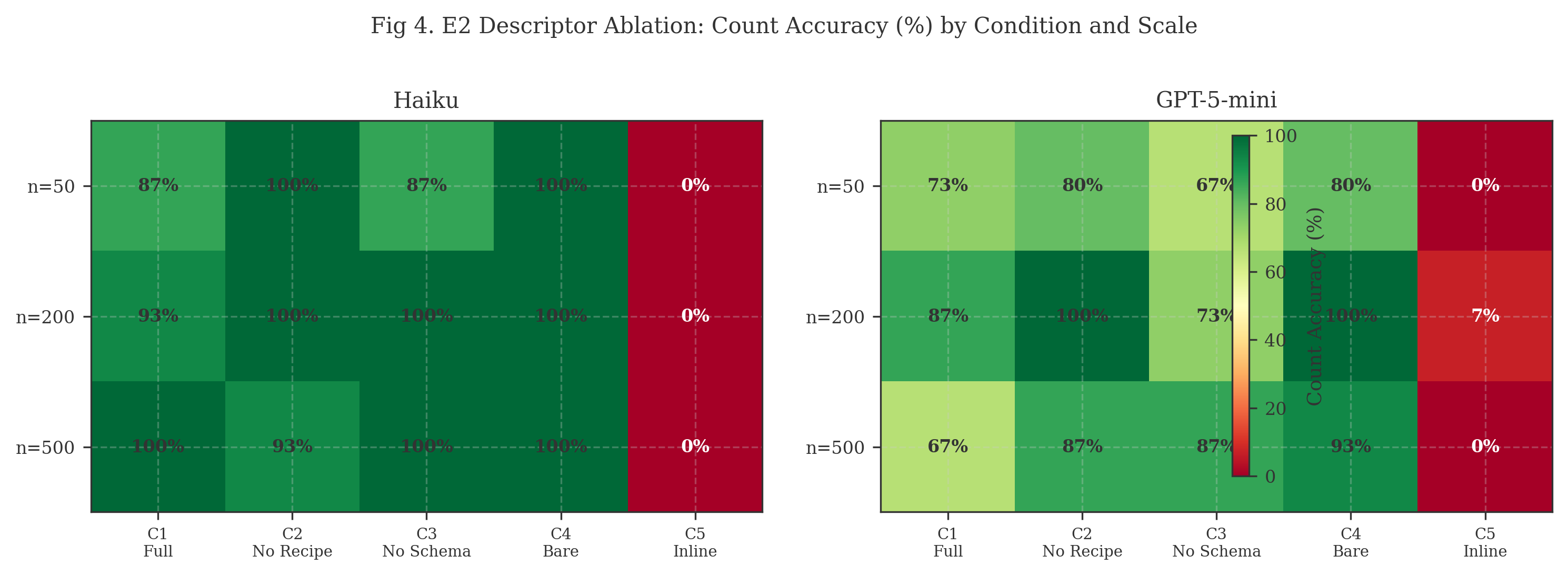
Table 6. E2 count accuracy (%) by condition, scale, and model.
| Condition | n=50 | n=200 | n=500 | |||
|---|---|---|---|---|---|---|
| Haiku | GPT-5-mini | Haiku | GPT-5-mini | Haiku | GPT-5-mini | |
| C1 Full LRO | 86.7 | 73.3 | 93.3 | 86.7 | 100.0 | 66.7 |
| C2 No Recipes | 100.0 | 80.0 | 100.0 | 100.0 | 93.3 | 86.7 |
| C3 No Schema | 86.7 | 66.7 | 100.0 | 73.3 | 100.0 | 86.7 |
| C4 Bare Pointer | 100.0 | 80.0 | 100.0 | 100.0 | 100.0 | 93.3 |
| C5 Inline | 0.0 | 0.0 | 0.0 | 6.7 | 0.0 | 0.0 |
Table 7. E2 mean count accuracy across all scales and models.
| Condition | Mean Accuracy |
|---|---|
| C4 Bare Pointer | 95.6% |
| C2 No Recipes | 93.3% |
| C3 No Schema | 85.6% |
| C1 Full LRO | 84.4% |
| C5 Inline | 1.1% |
Analysis. Descriptor components have no measurable positive impact on count accuracy. C4 (bare pointer) outperforms C1 (full descriptor) by 11 percentage points. This inverts the expected gradient: more metadata correlates with lower accuracy, not higher.
The explanation is behavioral. Under natural prompting, agents proceed directly to bash + jq regardless of descriptor richness. Rich descriptors may induce the agent to spend turns analyzing metadata (reading schemas, reviewing recipes) before executing the straightforward grep that solves the task. The bare pointer eliminates this distraction.
The critical factor is file access combined with shell capability. All four LRO conditions provide these. For this task type, the descriptor’s supplementary metadata is noise the agent can infer or ignore.
C5 (inline) fails completely, confirming E1’s finding.
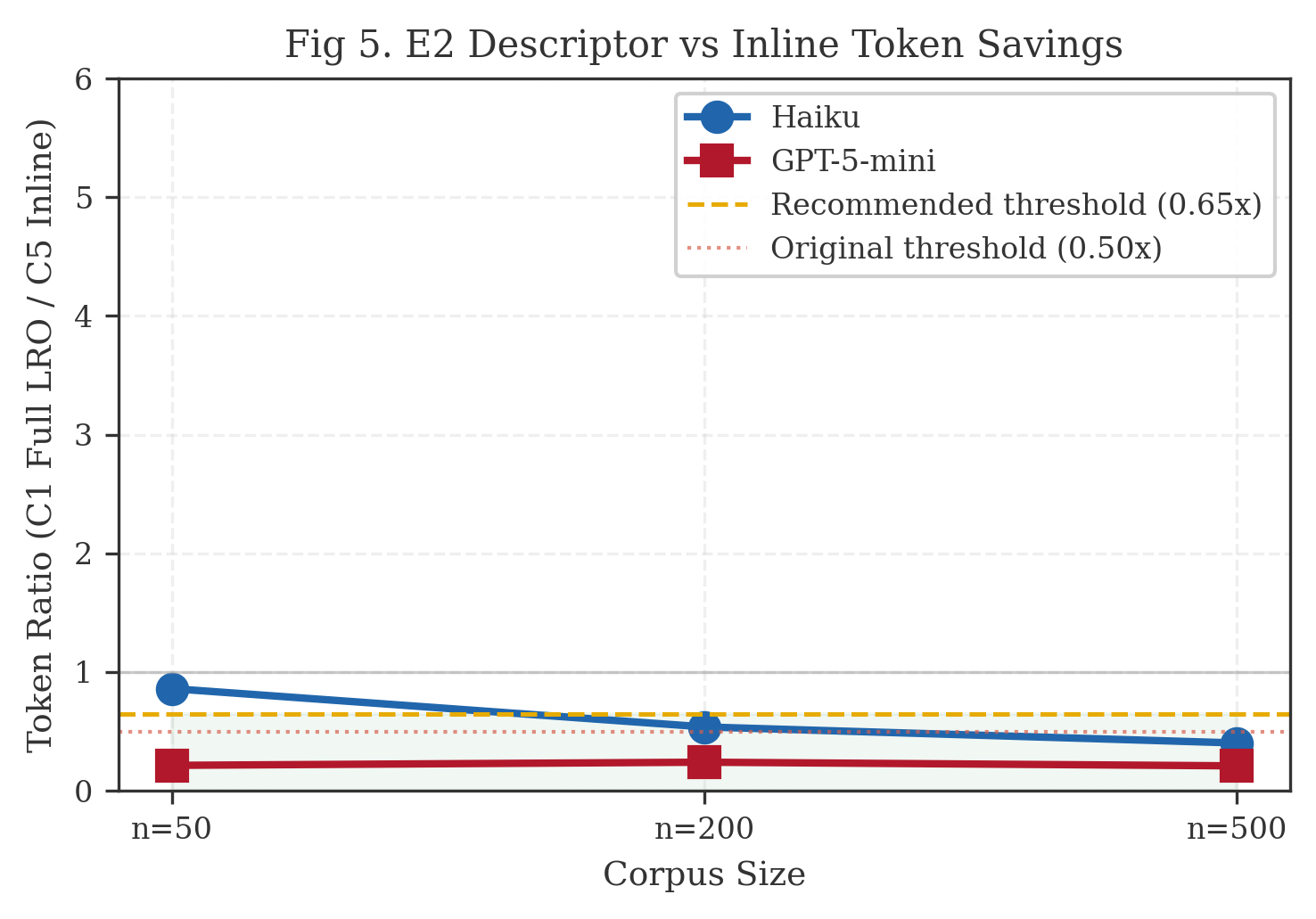
Guided prompting variant (E2g). To distinguish “descriptors are useless” from “agents don’t consume descriptors,” we ran a parallel set of four guided conditions (C1g—C4g) with identical descriptor content but an extended system prompt requiring the agent to consult line_schema, scan jq_recipes, and follow guidance before querying. The guided conditions show marginal accuracy differences from their natural counterparts; guided prompting does not meaningfully change the outcome for this task class. The bare pointer remains competitive even when agents are coached to use descriptor metadata.
Experiment 3: Recipe Utility
Section titled “Experiment 3: Recipe Utility”Claim under test: Extraction recipes in the descriptor help agents navigate offloaded files.
Design: Two conditions, Recipe (descriptor includes jq_recipes) and NoRecipe (descriptor omits jq_recipes), with identical system prompts. Both conditions provide bash access and the same JSONL file.
Results:
Table 8. E3 count accuracy (%) by condition, scale, and model.
| Condition | n=50 | n=200 | n=500 | |||
|---|---|---|---|---|---|---|
| Haiku | GPT-5-mini | Haiku | GPT-5-mini | Haiku | GPT-5-mini | |
| Recipe | 93.3 | 73.3 | 86.7 | 100.0 | 73.3 | 93.3 |
| NoRecipe | 93.3 | 86.7 | 86.7 | 93.3 | 100.0 | 86.7 |
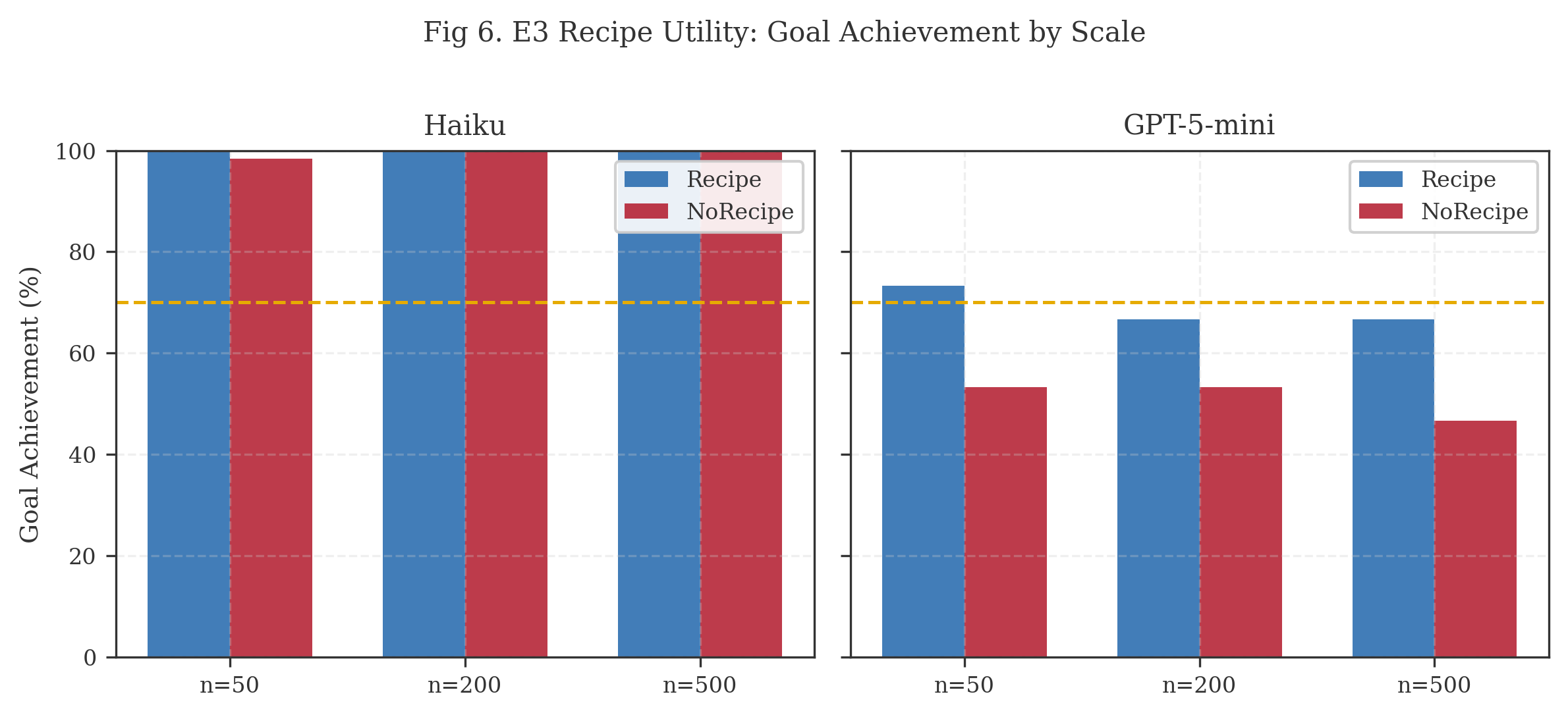
Table 9. E3 goal achievement (%): fraction of extraction queries using library-aligned patterns.
| Condition | n=50 | n=200 | n=500 | |||
|---|---|---|---|---|---|---|
| Haiku | GPT-5-mini | Haiku | GPT-5-mini | Haiku | GPT-5-mini | |
| Recipe | 100.0 | 73.3 | 100.0 | 66.7 | 100.0 | 66.7 |
| NoRecipe | 98.3 | 53.3 | 100.0 | 53.3 | 100.0 | 46.7 |
Table 10. E3 pattern alignment score (0—1 scale).
| Condition | n=50 | n=200 | n=500 | |||
|---|---|---|---|---|---|---|
| Haiku | GPT-5-mini | Haiku | GPT-5-mini | Haiku | GPT-5-mini | |
| Recipe | 0.783 | 0.683 | 0.800 | 0.667 | 0.824 | 0.578 |
| NoRecipe | 0.758 | 0.500 | 0.633 | 0.456 | 0.750 | 0.417 |
Analysis. Count accuracy shows no meaningful difference between Recipe and NoRecipe conditions. Both achieve 73—100% across all scales and models. The agent formulates effective jq queries whether or not recipes are provided.
Recipe utility is model-dependent. Haiku achieves 98—100% goal achievement in both conditions; it does not need recipes. GPT-5-mini shows a +13—20 percentage point advantage with recipes (67—73% vs 47—53%), indicating that recipes serve as scaffolding for models with weaker tool-use capability.
Pattern alignment confirms this divergence. With recipes, GPT-5-mini produces queries scoring 0.58—0.68 alignment; without, alignment drops to 0.42—0.50. Recipes help the weaker model produce queries closer to expected patterns.
Experiment 4: Filter Descriptor Ablation
Section titled “Experiment 4: Filter Descriptor Ablation”Claim under test: Descriptor components matter more for complex multi-field filter queries than for simple ID lookups. Rich descriptors (schema, recipes) should outperform bare pointers on tasks that require combining namespace filtering, priority comparison, and content search.
Design: Same five descriptor conditions as E2 (C1—C5), applied exclusively to aggregate_filter tasks. Each task requires the agent to identify memories matching a conjunction of criteria: a specific namespace prefix, a priority threshold (comparison operator + value), and a content keyword. The correct answer requires scanning the full corpus and applying all three filters simultaneously --- a task that demands either schema knowledge (to locate the right fields) or exploratory shell work (to discover the JSONL structure).
Results:
Table 11. E4 count accuracy (%) by condition across all scales and models.
| Condition | Mean Accuracy | Content Tokens | LLM Cost (tokens) |
|---|---|---|---|
| C1 Full LRO | 12.9% | 38,497 | 321,597 |
| C2 No Recipes | 12.9% | 35,409 | 291,537 |
| C3 No Schema | 12.9% | 41,819 | 345,560 |
| C4 Bare Pointer | 12.9% | 42,354 | 341,761 |
| C5 Full Inline | 0.0% | 70,548 | 661,071 |
Analysis. Three findings emerge from the filter ablation.
First, the descriptor paradox extends to complex tasks. All four LRO conditions achieve identical 12.9% accuracy, with no measurable advantage from rich descriptors (C1) over bare pointers (C4). Even on tasks explicitly designed to benefit from schema and recipe information --- where the agent must locate specific fields (namespace, priority, content text) and apply comparison operators --- the additional metadata provides no lift. The agent’s shell exploration strategy (inspecting the first few lines, inferring structure, composing filters) matches the effectiveness of consuming pre-computed schema definitions.
Second, filter tasks are substantially harder than ID lookup. The 12.9% accuracy across LRO conditions compares to 84—96% on E2’s ID lookup tasks under the same descriptor configurations. Multi-criteria conjunction queries expose a genuine capability gap: the agent must chain multiple jq select() predicates or equivalent shell operations, handle nested field paths, and apply comparison operators correctly. The difficulty is not in finding the file or understanding the format (bare pointer suffices for that) but in composing correct multi-predicate queries against structured data.
Third, the inline ceiling remains at zero. C5 achieves 0% accuracy on filter tasks, consistent with E1 and E2 findings. Inline delivery fails regardless of task complexity.
The C1 vs C4 delta of +0.0 percentage points contradicts the hypothesis that motivated E4. We designed this experiment expecting schema and recipe information to help on complex tasks where the agent cannot rely on simple grep. Instead, the data shows that descriptor metadata is orthogonal to task difficulty: both simple and complex tasks yield the same bare-pointer parity. The descriptor paradox is not task-type-specific; it reflects how current models interact with structured tool metadata.
Token efficiency follows the expected pattern: C5 inline consumes 2x the tokens of LRO conditions (661K vs 292—346K), with C2 (No Recipes) being the most token-efficient LRO variant.
Cross-Model Findings
Section titled “Cross-Model Findings”| Metric | Haiku 4.5 | GPT-5-mini |
|---|---|---|
| Mean LRO count accuracy (ID lookup) | 91.1% | 77.8% |
| Mean inline count accuracy | 0.0% | 2.2% |
| Mean Inline+Code accuracy | 0.0% | 0.0% |
| Mean LRO tokens (n 200) | 158K | 233K |
| Mean inline tokens (n 200) | 346K | 567K |
| E3 recipe benefit (goal achievement) | None (+0pp) | +13—20pp |
| E2 best condition (ID lookup) | C4 Bare (100%) | C2/C4 (87—100%) |
| E4 filter accuracy (all conditions) | 12.9% | 12.9% |
Both models fail completely on inline delivery. The 0% count accuracy is model-independent: the failure mode is architectural (pagination-induced state loss), not capability-based. The Inline+Code result extends this finding: even with a persistent Python execution environment for programmatic accumulation, neither model achieves non-zero accuracy. This is the strongest evidence that LRO addresses an architectural failure rather than compensating for weak models.
Haiku is more efficient with LRO, producing shorter and more targeted jq commands (158K vs 233K mean tokens). GPT-5-mini has higher variance and benefits more from recipe scaffolding. LRO’s utility holds across model capabilities while its efficiency improves with model quality.
On filter tasks (E4), both models converge to 12.9% accuracy regardless of descriptor configuration. The uniformity across models indicates that multi-criteria filtering difficulty is not model-dependent at current capability levels: both hit the same compositional barrier when constructing multi-predicate queries.
Discussion
Section titled “Discussion”Reframing LRO’s Value Proposition
Section titled “Reframing LRO’s Value Proposition”The theoretical analysis (Section 5) frames LRO as a cost optimization, trading disk I/O for context savings. The empirical results demand a reframing: LRO’s primary value is enabling whole-corpus operations that are failure-prone under naive inline pagination. The 0—7% inline accuracy at scale is not a benchmark weakness or a task design artifact; it demonstrates a fundamental limitation of paginated in-context data delivery for aggregation tasks.
LRO is not an optional optimization for cost-sensitive deployments. For agent tasks that require processing a complete result set --- counting, filtering, aggregation, deduplication --- it is a reliability requirement when the result set exceeds a single tool response.
The Descriptor Paradox
Section titled “The Descriptor Paradox”The E2 ablation reveals a paradox: the full descriptor (C1), designed to help agents navigate offloaded data, underperforms the bare pointer (C4). Three hypotheses were proposed:
- Distraction cost. Rich descriptors induce agents to spend turns analyzing metadata before executing the simple operation that solves the task. The bare pointer eliminates this distraction.
- Task-type dependency. ID lookup tasks have a trivial extraction pattern (
grepfor UUIDs). More complex tasks (e.g., “find all incidents in namespace X with priority > 3 that mention product Y”) should benefit from schema and recipe information that the agent cannot easily infer. - Training distribution. Current models are trained on tool-use patterns where they receive data and process it directly. The descriptor pattern (receive metadata about data and decide how to access it) may require explicit training signal or prompting to elicit optimal behavior.
E4 directly tests hypothesis 2 and refutes it. Multi-field filter tasks --- requiring namespace filtering, priority comparison, and content search in conjunction --- show identical accuracy across all descriptor configurations (12.9% for C1—C4). Schema and recipe metadata provide no measurable advantage even on tasks explicitly designed to benefit from them. The agent’s strategy of inspecting file structure through exploratory shell commands is as effective as consuming pre-computed metadata, regardless of task complexity.
The guided prompting variant (E2g) refutes hypothesis 3 for ID lookup tasks: guided conditions do not outperform natural ones even with explicit coaching.
With hypotheses 2 and 3 refuted by evidence, hypothesis 1 (distraction cost) and a fourth possibility remain: agents have internalized sufficient knowledge of common data formats (JSON, JSONL) to navigate structured files without external schema.
Prioritize the file reference and shell access. Include descriptor metadata (schema, recipes, guidance) as forward-compatible scaffolding for models that may consume structured tool metadata more effectively, but do not treat it as a functional requirement. For current-generation models, the bare pointer is sufficient across both simple and complex task types.
Recipe Utility as Capability Scaffolding
Section titled “Recipe Utility as Capability Scaffolding”E3 reveals that recipe utility is a proxy for model capability. Haiku formulates effective jq queries without recipes; its tool-use training is sufficient. GPT-5-mini shows +13—20pp improvement in goal achievement with recipes, suggesting that extraction templates compensate for weaker tool-use capability.
For descriptor design, this implies adaptive recipe inclusion: implementations can omit recipes for capable models and include them for weaker ones, with descriptor richness scaling inversely with model capability.
Limitations
Section titled “Limitations”Task-type coverage. The evaluation covers ID lookup (counting UUIDs matching known targets) and multi-field filtering (conjunction queries over namespace, priority, and content). Filter tasks in E4 extend beyond the narrow ID lookup case and show that the descriptor paradox holds across task complexity levels. Additional task types --- cross-record aggregation, temporal reasoning, multi-hop entity resolution --- would extend generalizability. The 12.9% accuracy on filter tasks identifies a capability frontier for future evaluation.
Scale constraints. The inline baseline is untestable beyond approximately n = 50 records because context overflow prevents completion. This is by design (LRO exists because inline fails at scale), but it means the LRO vs. inline accuracy comparison is only meaningful at small n, where LRO’s advantage is already decisive.
Two-model coverage. The evaluation uses two models (Haiku 4.5, GPT-5-mini) spanning different capability levels and providers. Broader coverage --- open-source models, larger frontier models --- would extend generalizability.
Practitioner references. References [4, 6, 10, 14, 17] are practitioner blog posts rather than peer-reviewed publications, cited for empirical observations and production patterns not yet formalized in the literature. Conceptual claims rest on peer-reviewed work [1—3, 5, 7—9, 11—13, 15—16, 19—24] and our own evaluation.
Specification and Implementation
Section titled “Specification and Implementation”LRO is specified as an open protocol-level pattern for MCP-compatible memory servers with three graduated conformance levels (Basic, Standard, Full; see Appendix F for details). Configuration is managed via a [prompt.offload] section with parameters for threshold (), TTL, and output directory. The complete specification, including configuration schema and conformance requirements, is available in the lro-bench repository.
The benchmark harness, task suites, and evaluation scripts used in Section 6 are open-source at github.com/zircote/lro-bench.
Conclusion
Section titled “Conclusion”Large Result Offloading addresses the mismatch between retrieval output cardinality and downstream consumption requirements in tool-augmented language model systems. The evaluation establishes that this mismatch is a capability boundary, not only a cost concern. Inline delivery of large result sets fails at 0—7% accuracy for whole-corpus operations --- a result that persists even when the agent is given a persistent Python execution environment (0% accuracy) --- while LRO achieves 73—100% accuracy on ID lookup tasks across two models and three corpus scales.
The contribution is fourfold:
-
Task enablement over cost optimization. LRO enables operations that are architecturally fragile under inline delivery. Token savings of 40—62% at scale are a secondary benefit; the primary contribution is eliminating pagination-induced state loss.
-
The descriptor paradox. The compact descriptor was designed as a typed API between the retrieval and reasoning subsystems. Ablation across two task types (ID lookup and multi-field filtering) reveals that a bare file pointer performs as well as a full descriptor under current model behavior. The finding holds across task complexity: even on multi-criteria filter tasks explicitly designed to benefit from schema and recipe metadata, no descriptor configuration outperforms the bare pointer. For current models, file access and shell capability are sufficient; structured metadata may matter for future models trained to consume it.
-
Task complexity as the frontier. Filter tasks requiring multi-criteria conjunction queries (namespace filtering, priority comparison, content search) achieve only 12.9% accuracy across all LRO conditions, compared to 84—96% on ID lookup tasks. The difficulty is not in accessing the data (LRO solves that) but in composing correct multi-predicate queries. This identifies compositional query construction as the next capability boundary for tool-augmented agents.
-
Model-dependent scaffolding. Extraction recipes provide no benefit for capable models but improve goal achievement by 13—20 percentage points for weaker ones. Descriptor richness should adapt to model capability.
The descriptor pattern extends beyond memory retrieval. As tool protocols like MCP mature, structuring tool output for agent consumption becomes a first-class design concern. Search results, log queries, API response aggregations, and multi-agent shared state all face the same context allocation trade-off. LRO’s formalization --- materialization, structured descriptor, extraction interface --- applies to any tool whose output exceeds what the consuming model needs in context.
Appendix
Section titled “Appendix”Appendix A: JSONL Property Advantages
Section titled “Appendix A: JSONL Property Advantages”| Property | Advantage |
|---|---|
| Line-oriented structure | Enables streaming consumption via standard Unix tools (tail, head, sed) |
Native jq compatibility | Extraction queries operate on individual lines without array slurping |
grep compatibility | Pattern matching works across single-line records without multi-line parsing |
| Append-friendly | No wrapper structure to maintain; new records append trivially |
| Partial read support | Arbitrary record access via line number without full-file parsing |
Appendix B: Extraction Query Library
Section titled “Appendix B: Extraction Query Library”| Category | Example Query | Purpose |
|---|---|---|
| Enumeration | tail -n +2 {file} | jq -r '[.title,.provenance.confidence] | @tsv' | Tabular listing of titles with scores |
| Filtering | tail -n +2 {file} | jq 'select(.namespace | startswith("_semantic"))' | Namespace-based subset selection |
| Search | tail -n +2 {file} | jq 'select(.title | test("keyword"; "i"))' | Case-insensitive keyword matching |
| Aggregation | tail -n +2 {file} | jq -s 'group_by(.namespace) | map({namespace:.[0].namespace, count: length})' | Distribution analysis |
| Ranking | tail -n +2 {file} | jq -s 'sort_by(-.provenance.confidence) |.[:10]' | Top-k extraction by score |
All recipes use tail -n +2 to skip the header line. Recipes are composable via Unix pipeline chaining, enabling the agent to construct compound queries from primitive operations.
Appendix C: Guidance Prompt Example
Section titled “Appendix C: Guidance Prompt Example”Results offloaded to JSONL (247 memories, ~38,285 tokens saved).File: /tmp/lro-recall-01JDEF7X2K.jsonlDetail level: full
Use the jq recipes above to extract specific data. Common patterns:- Browse: recipe #1 (titles with namespaces)- Filter: recipe #2 (by namespace) or #3 (by keyword)- Analyze: recipe #6 (count by namespace)
Read the file directly only if you need the complete dataset.The header line (line 1) contains metadata; memory objects start at line 2.The guidance prompt is the descriptor’s natural-language bridge to the agent. It orients the agent to the offloaded state, suggests starting points, and sets the expectation that selective extraction is the normal path.
Appendix D: Deployment Matrix
Section titled “Appendix D: Deployment Matrix”Table D1. LRO applicability across deployment environments.
| Environment | Filesystem | Shell | LRO Mode | Descriptor Utility |
|---|---|---|---|---|
| Claude Code, Cursor, Windsurf | Local | Yes | Full | Extraction queries + metadata |
| IDE agents (Copilot, Cody) | Local | Limited | Partial | File read possible, jq may require fallback |
| Remote MCP (streamable-http) | Server-side | Client-side | Disabled | Metadata only (file path unreachable) |
| Remote MCP + local proxy | Local (proxy) | Yes | Full | Proxy materializes locally; shell extraction |
| Remote MCP + native extraction | Local (proxy) | Not required | Full | Proxy materializes locally; MCP tool extraction |
| Web chat (ChatGPT, Claude.ai) | None | None | Disabled | Metadata only (summary, counts, score range) |
| Web chat + native extraction proxy | Local (proxy) | Not required | Full | MCP tool extraction; no shell needed |
| Mobile applications | None | None | Disabled | Metadata only |
| Serverless agents (Lambda) | Ephemeral | Yes | Conditional | Full if same execution context; disabled otherwise |
The proxy-enabled rows show that the filesystem and shell constraints are deployment-level, not protocol-level: a local proxy interposes between client and remote server to materialize JSONL files on the client’s filesystem, and a native extraction tool replaces shell-based jq with an MCP tool call. The combination requires a local process, available in most environments except pure browser tabs and mobile apps without companion services.
Appendix E: Alternative Extraction Interface Details
Section titled “Appendix E: Alternative Extraction Interface Details”Local proxy materialization. When the memory server runs remotely via streamable-http, a lightweight local MCP server (connected to the LLM client via stdio) can proxy tool calls to the remote server, receive the full result set, apply the LRO interceptor locally, and write the JSONL file to the client’s filesystem. The remote server returns results inline (bypassing its own LRO) when it detects a proxy client; the proxy materializes locally using the same threshold and JSONL conventions. Storage, search, and enrichment remain on the shared server; the proxy holds only ephemeral JSONL files for the current session. The trade-off is a double-hop latency penalty: every tool call traverses stdio to the proxy, then HTTP to the remote server, before the result can be materialized and returned. For large result sets where LRO activates, this overhead is small relative to the search and serialization time on the server; for small result sets returned inline, the proxy adds a fixed round-trip cost that would not exist in a direct connection.
Native MCP extraction tool. A local MCP server (whether a standalone proxy or a full local implementation) can expose extraction as a native MCP tool rather than relying on the agent’s shell access. The tool accepts a file path, a recipe identifier or custom jq expression, and optional substitution parameters, then executes the extraction internally and returns the filtered subset as a tool result. The agent issues a single MCP tool call instead of composing a tail | jq pipeline. The descriptor’s guidance prompt references the extraction tool by name, so the agent learns the extraction interface from the tool response itself rather than from prior configuration.
This shifts the guidance prompt from a static template to a tool-generated artifact. The implementation that provides the extraction tool owns the guidance content, so the prompt stays accurate as the tool’s interface changes. The cost is implementation complexity: the MCP server must parse and evaluate jq expressions (or an equivalent filter language) internally, and must validate that file_path parameters resolve within the configured output_dir to prevent path traversal. Arbitrary jq expressions from the agent also require sandboxing to avoid resource exhaustion (e.g., unbounded group_by on large files).
Appendix F: Conformance Levels
Section titled “Appendix F: Conformance Levels”- Level 1 (Basic): Threshold detection and JSONL materialization. Descriptor contains file reference and summary statistics.
- Level 2 (Standard): Level 1 plus schema definition and extraction query library.
- Level 3 (Full): Level 2 plus custodial cleanup, error fallback to inline truncation, and observability events.
References
Section titled “References”- Zhang, Y. et al. “Solving Context Window Overflow in AI Agents.” arXiv preprint arXiv:2511.22729, 2025. https://arxiv.org/abs/2511.22729
- Packer, C. et al. “MemGPT: Towards LLMs as Operating Systems.” arXiv preprint arXiv:2310.08560, 2023. https://arxiv.org/abs/2310.08560
- Feng, S. et al. “A-RAG: Scaling Agentic Retrieval-Augmented Generation.” arXiv preprint arXiv:2602.03442, 2026. https://arxiv.org/abs/2602.03442
- Zujkowski, W. “From 150K to 2K Tokens: How Progressive Context Loading Revolutionizes LLM Development Workflows.” 2025. https://williamzujkowski.github.io/posts/from-150k-to-2k-tokens-how-progressive-context-loading-revolutionizes-llm-development-workflows/
- Li, Y. et al. “ACON: Optimizing Context Compression for Long-horizon LLM Agents.” arXiv preprint arXiv:2510.00615, 2025. https://arxiv.org/abs/2510.00615
- JetBrains Research. “Cutting Through the Noise: Smarter Context Management for LLM Agents.” 2025. https://blog.jetbrains.com/research/2025/12/efficient-context-management/
- Jiang, H. et al. “LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models.” Microsoft Research, 2023. https://arxiv.org/abs/2310.05736
- Li, Y. et al. “Unlocking Context Constraints of LLMs: Enhancing Context Efficiency of LLMs with Self-Information-Based Content Filtering.” arXiv preprint arXiv:2304.12102, 2023. https://arxiv.org/abs/2304.12102
- Li, F. et al. “Database Perspective on LLM Inference Systems.” Proceedings of the VLDB Endowment 18, 2025. https://www.vldb.org/pvldb/vol18/p5504-li.pdf
- Oracle. “Comparing File Systems and Databases for Effective AI Agent Memory Management.” Oracle Developer Blog, 2025. https://blogs.oracle.com/developers/comparing-file-systems-and-databases-for-effective-ai-agent-memory-management
- Xu, B. et al. “ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models.” arXiv preprint arXiv:2305.18323, 2023. https://arxiv.org/abs/2305.18323
- Wang, X. et al. “Executable Code Actions Elicit Better LLM Agents.” arXiv preprint arXiv:2402.01030, 2024. https://arxiv.org/abs/2402.01030
- Chen, L. et al. “EcoAct: Economic Agent Determines When to Register What Action.” OpenReview, 2024. https://openreview.net/forum?id=OyWreBlvIE
- LangChain. “Context Engineering for Agents.” LangChain Blog, 2025. https://blog.langchain.com/context-engineering-for-agents/
- Prabhu, A. et al. “vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention.” arXiv preprint arXiv:2405.04437, 2024. https://arxiv.org/abs/2405.04437
- Kwon, W. et al. “Efficient Memory Management for Large Language Model Serving with PagedAttention.” Proceedings of SOSP, 2023.
- Eckstein, J. “MCP and Context Overload: Why More Tools Make Your AI Agent Dumber.” EclipseSource Blog, 2026. https://eclipsesource.com/blogs/2026/01/22/mcp-context-overload/
- IBM Research. “Preventing Multimodal Cross-Domain Resource Abuse in MCP Tools.” 2025. https://research.ibm.com/publications/preventing-multimodal-cross-domain-resource-abuse-in-mcp-tools
- Zhang, Q. et al. “MOSS: Enabling Code-Driven Evolution and Context Management for AI Agents.” arXiv preprint arXiv:2409.16120, 2024. https://arxiv.org/abs/2409.16120
- Liu, N. F. et al. “Lost in the Middle: How Language Models Use Long Contexts.” Transactions of the Association for Computational Linguistics 12, 2024. https://arxiv.org/abs/2307.03172
- Kate, S. et al. “LongFuncEval: Assessing LLM Function Calling Under Extended Contexts.” arXiv preprint arXiv:2505.10570, 2025. https://arxiv.org/abs/2505.10570
- Huang, W.-C. et al. “Rethinking Memory Mechanisms of Foundation Agents in the Second Half: A Survey.” arXiv preprint arXiv:2602.06052, 2026. https://arxiv.org/abs/2602.06052
- Zhang, Z. et al. “Memory in the Age of AI Agents.” arXiv preprint arXiv:2512.13564, 2025. https://arxiv.org/abs/2512.13564
- UK AI Safety Institute. “Inspect AI: A Framework for Large Language Model Evaluations.” 2024. https://inspect.ai-safety-institute.org.uk/
- He, Z. et al. “MemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks.” arXiv preprint arXiv:2602.16313, 2026. https://arxiv.org/abs/2602.16313
- Li, J. et al. “AgentLongBench: A Controllable Long Benchmark for Long-Contexts Agents via Environment Rollouts.” arXiv preprint arXiv:2601.20730, 2026. https://arxiv.org/abs/2601.20730