AI Agents in 2026: Beyond Chat to Autonomous Development
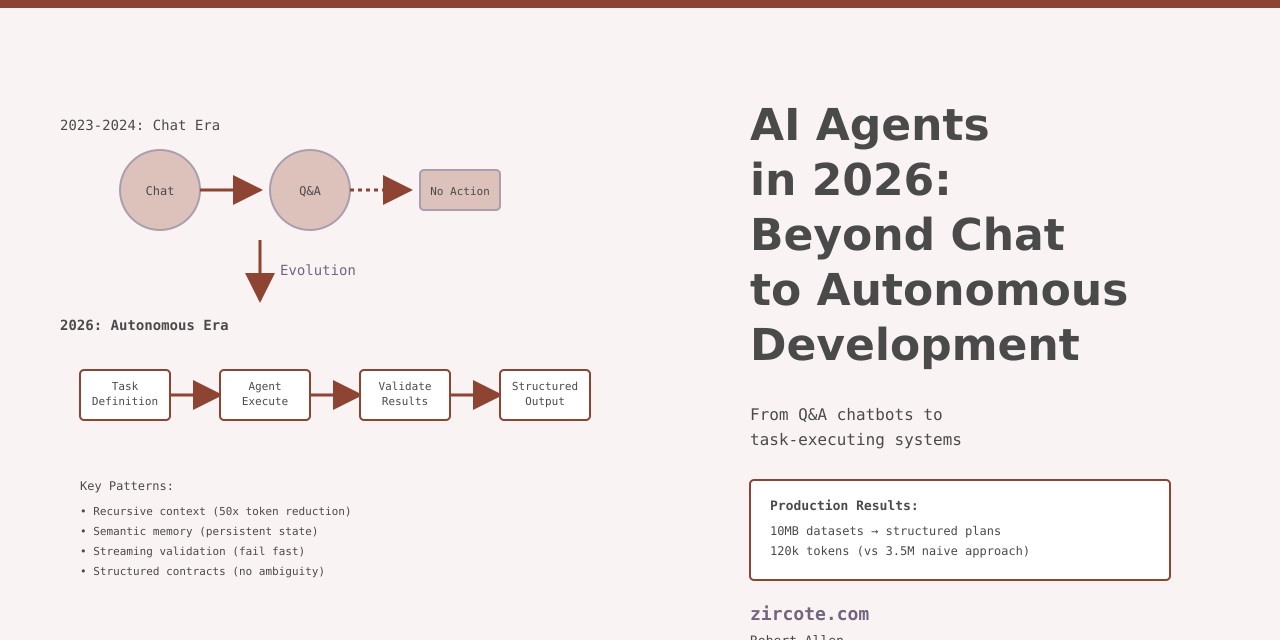

The chatbot era is over. Not because chat interfaces failed, but because they solved the wrong problem.
I spent 2025 building AI agents that do work, not conversation. Tools like rlm-rs that parse 10MB CSV exports from PagerDuty and produce 16-week project plans complete with Jira tickets, runbooks, and operational guides. All under 120,000 tokens. The shift from “AI that answers” to “AI that executes” changes everything about how we build software.
The Q&A Dead End
ChatGPT launched in late 2022. By mid-2023, every company had added a chat interface to their product. Most of those experiments are dead now.
The pattern was predictable:
- Build chat UI
- Connect to LLM API
- Watch users ask questions
- Realize they wanted actions, not answers
- Bolt on workflow features
- Architecture collapses under edge cases
Chat works for information retrieval. It breaks for task execution. The fundamental issue is modal friction: every action requires another round of clarification. “Should I proceed?” “Are you sure?” “Which option?” Each question costs latency, attention, and context.
Task Execution: Different Architecture
Autonomous agents need different foundations. Not chat models with API calls bolted on, but systems designed for multi-step execution with verification loops.
Three requirements emerged from building production agent tools:
1. Context Beyond Windows
Standard context windows choke on real work. A PagerDuty export for a medium-sized incident response history hits 10-15MB easily. That’s 3-4 million tokens at GPT-4 rates. Even with 200k context windows, you can’t fit six months of operational data.
rlm-rs v2.0 implements Recursive Language Models (based on arXiv:2512.24601). The approach processes snippets recursively with fast retrieval. Instead of jamming everything into context, it builds a searchable index and pulls relevant sections on demand.
Result: Process datasets two orders of magnitude larger than context windows with minimal token overhead. The plan generation that took 120k tokens would have consumed 3.5M tokens with naive context stuffing, a 30x reduction.
2. Memory That Persists
Stateless AI is a solved problem technically. We know how to store conversation history. The real challenge is semantic memory: capturing decisions, patterns, blockers, and learnings across sessions.
mnemonic implements this through a file system compatible with Obsidian vaults, version controlled by git if you choose. Ontology is a first-class requirement: not optional metadata, but structured semantic relationships that enable progressive disclosure.
Three detail levels reduce token consumption by 10-50x:
- SUMMARY: Decision and outcome only
- FULL: Complete context and rationale
- FILES: Actual code changes and diffs
Signal detection theory automatically identifies what to capture. Most interactions are noise. Mnemonic tracks decisions that change system behavior, unblock progress, or establish patterns.
3. Autonomous Research and Planning
Humans are terrible at comprehensive research under time pressure. AI agents can search, synthesize, and structure information faster than you can frame the question.
sigint runs autonomous market research: elicit requirements, execute multi-source research, generate structured reports, create GitHub issues for tracking. All with state persistence across sessions via subcog.
The workflow: Define research objective, agent conducts research autonomously, produces executive summary with market sizing (TAM/SAM/SOM), competitive landscape, SWOT analysis, technology assessment, recommendations, and risk factors. Output in markdown and HTML.
Key innovation: Three-valued logic (INC/DEC/CONST) for trend analysis when data is sparse. Traditional analysis waits for complete information. Three-valued logic makes early-stage decisions explicit about uncertainty.
Patterns That Work
After building four production agent tools in 2025, these patterns consistently delivered results:
Pattern 1: Streaming Validation
Don’t wait for completion to validate. Stream partial results and fail fast. documentation-review validates docs as they generate, catching outdated examples, missing error cases, and style violations before the agent finishes.
Pattern 2: Structured Output Contracts
Natural language output is fine for humans. Agents need structured data. Every tool I built uses strict output schemas: JSON Schema for interchange, Protocol Buffers for internal processing. No free-form text in critical paths.
Pattern 3: Explicit Uncertainty
Agents hallucinate. Accept it, design for it, surface it. sigint reports confidence scores on every claim. Low confidence triggers human review. Agents don’t guess silently.
Pattern 4: Ontology-First Memory
Unstructured memory doesn’t scale. After 100 interactions, retrieval becomes random. mnemonic requires ontology for every stored item: not tags, not categories, but semantic relationships in a graph.
Pitfalls Nobody Mentions
The marketing material shows perfect demos. Reality is messier.
Pitfall 1: Token Economics Change Everything
Building with AI introduces operational cost that scales with usage. You can’t experiment freely anymore. Every iteration costs money.
I built a prototype that cost real money in API calls before I realized the approach was wrong. Software used to be free to iterate. Now there’s a meter running.
Pitfall 2: Non-Determinism Breaks Testing
Traditional tests assume deterministic behavior. Run the same input twice, get the same output. AI agents violate this constantly.
Solution: Test invariants, not exact outputs. Document length within bounds? Required fields present? Links valid? Schema compliance? Test those. Don’t test exact wording.
Pitfall 3: Latency Kills Workflows
LLM calls take seconds. Human attention spans are measured in hundreds of milliseconds. Any workflow that requires multiple sequential LLM calls feels broken.
Batch operations. Parallel execution. Caching. Precomputation. Do anything to hide latency.
rlm-rs processes chunks in parallel, reducing wall-clock time from 45 seconds to 8 seconds for the same logical operation.
Pitfall 4: Versioning Is Hell
Model providers change behavior without warning. Your agent works perfectly Tuesday morning. Wednesday afternoon, same code produces garbage.
Pin model versions. Test against version changes. Budget for re-tuning.
Production Learnings
What I got wrong building these tools:
Overestimated consistency: Early prototypes assumed agents would execute reliably. They don’t. Added retry logic, validation, and fallbacks everywhere.
Underestimated context leakage: Information from one session bleeding into another caused subtle bugs. Isolated contexts rigorously now.
Ignored token counting: Early versions of subcog burned unnecessary tokens because I didn’t instrument carefully. Token telemetry is mandatory.
Trusted natural language interfaces: CLI tools need explicit contracts, not conversational interfaces. Switched to structured input formats.
What’s Next
Three areas I’m focused on for 2026:
Multi-Agent Orchestration
Single agents hit capability ceilings quickly. The intuitive response is orchestrating specialized agents, though recent research from Google suggests this adds complexity without proportional gains.
The tradeoff: coordination overhead versus specialized capability. For well-defined domains with clear boundaries, multiple agents can work. For fluid, exploratory tasks, a single capable agent often performs better.
Formal Verification
Current validation is ad-hoc. Need formal methods to prove agent behavior meets specifications.
Exploring temporal logic assertions: “Agent must validate input before execution”, “Output must be generated within 30 seconds”, “No sensitive data in logs”.
Cost Optimization
Token costs matter for production use. Researching compression techniques, caching strategies, and model distillation to reduce operational expenses by 10x.
Practical Recommendations
If you’re building AI agents in 2026:
-
Start with structured output: Define schemas before prompts. Enforce validation.
-
Build observability: Track token usage, performance metrics, resource consumption, and financial costs. Costs add up invisibly across all layers.
-
Build memory systems: Stateless agents don’t scale. Invest in semantic memory early.
-
Test invariants, not content: Exact output matching breaks. Test structural properties.
-
Design for latency: Multiple sequential LLM calls kill UX. Batch, parallelize, cache.
-
Isolate contexts: Session leakage causes subtle bugs. Clean isolation is worth the complexity.
-
Surface uncertainty: When confidence is low, say so. Silent hallucinations are worse than visible uncertainty.
Conclusion
AI agents in 2026 are task executors, not conversationalists. The tools I built this year process datasets, maintain memory across sessions, conduct autonomous research, and generate production artifacts.
The shift changes development fundamentally. You’re no longer writing code that processes data. You’re orchestrating agents that do the processing for you.
That transition brings new patterns: recursive context handling, semantic memory, streaming validation, structured contracts. It also brings new pitfalls: token economics, non-determinism, latency sensitivity, version instability.
The industry is figuring this out in real time. Many organizations deploying AI agents are already reporting measurable ROI. The technology works. The challenge now is engineering discipline: designing systems that harness autonomous execution without collapsing under complexity.
If you want to explore these tools:
- rlm-rs: Recursive processing for massive datasets
- mnemonic: Git-native semantic memory
- sigint: Autonomous market research
- documentation-review: Automated documentation QA
Or reach out if you’re building similar infrastructure. This space is evolving fast, and practical experience matters more than theory.