From Paper to Production: Processing a Gigabyte with RLM
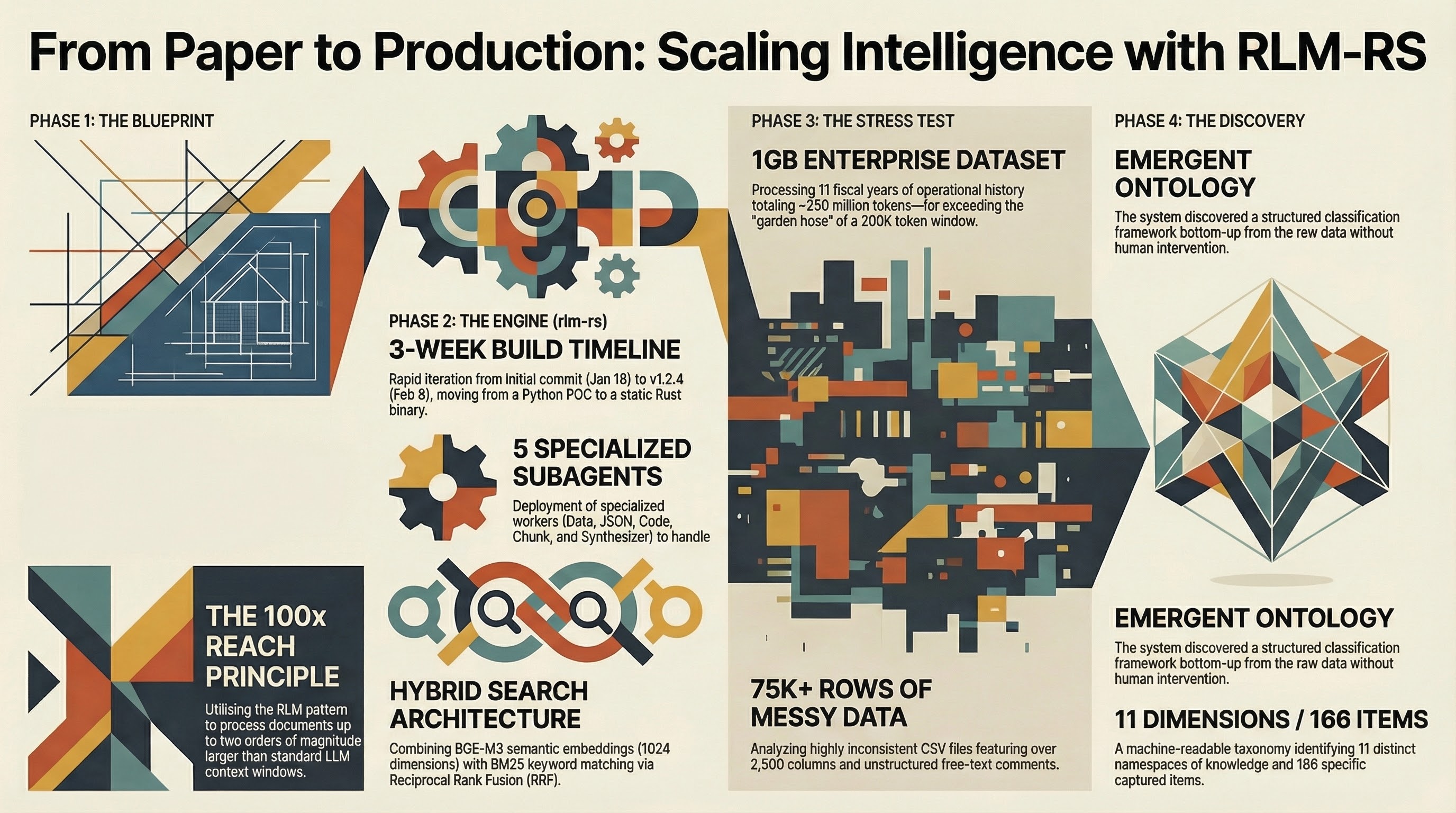
The Wall
I had the data. Over 75,000 rows of enterprise support data spanning 11 fiscal years, exported as CSV files. Some of the raw text files ran to 400MB each. In total, roughly a gigabyte of operational history for a large company — the kind of dataset that should contain answers to questions nobody had thought to ask yet.
The problem was not getting the data. The problem was doing anything useful with it.
Modern LLMs have context windows of 100,000 to 200,000 tokens. A gigabyte of text is approximately 250 million tokens. That is a gap of three orders of magnitude. You cannot stuff a gigabyte into a 200K-token window any more than you can pour a swimming pool through a garden hose.
The naive approach — “just summarize it” — does not work at this scale. You can summarize a document. You can summarize a thousand documents if you are patient. But summarization throws away the structure. It compresses the signal along with the noise. What I needed was not a summary. I needed analysis. I needed to find patterns across 11 years of data that no single person had the time or attention span to find by reading row by row.
I had been using LLMs for code analysis and development for a while. I manage 198 personal repositories and many more professionally. I run a farm. I work a full-time job. There is no team. Every tool I build has to work at scale without babysitting, or it is not worth building. And the data sitting in those CSV files represented a real opportunity — if I could figure out how to get an LLM to actually work through it instead of skimming the surface.
That was the wall. Not a lack of intelligence in the model. A lack of reach.
Finding the Pattern
I found John Adeojo’s Python implementation first — claude_code_RLM on GitHub, by brainqub3. It was a working proof of concept for using recursive sub-LLM calls to process documents that exceeded a single context window. It worked. I could see the potential immediately.
From there I traced back to the research paper: Recursive Language Models by Alex L. Zhang, Tim Kraska, and Omar Khattab at MIT CSAIL (arXiv:2512.24601, 2025). The paper formalizes something that feels obvious once you hear it but that most people (including me) had not thought through rigorously.
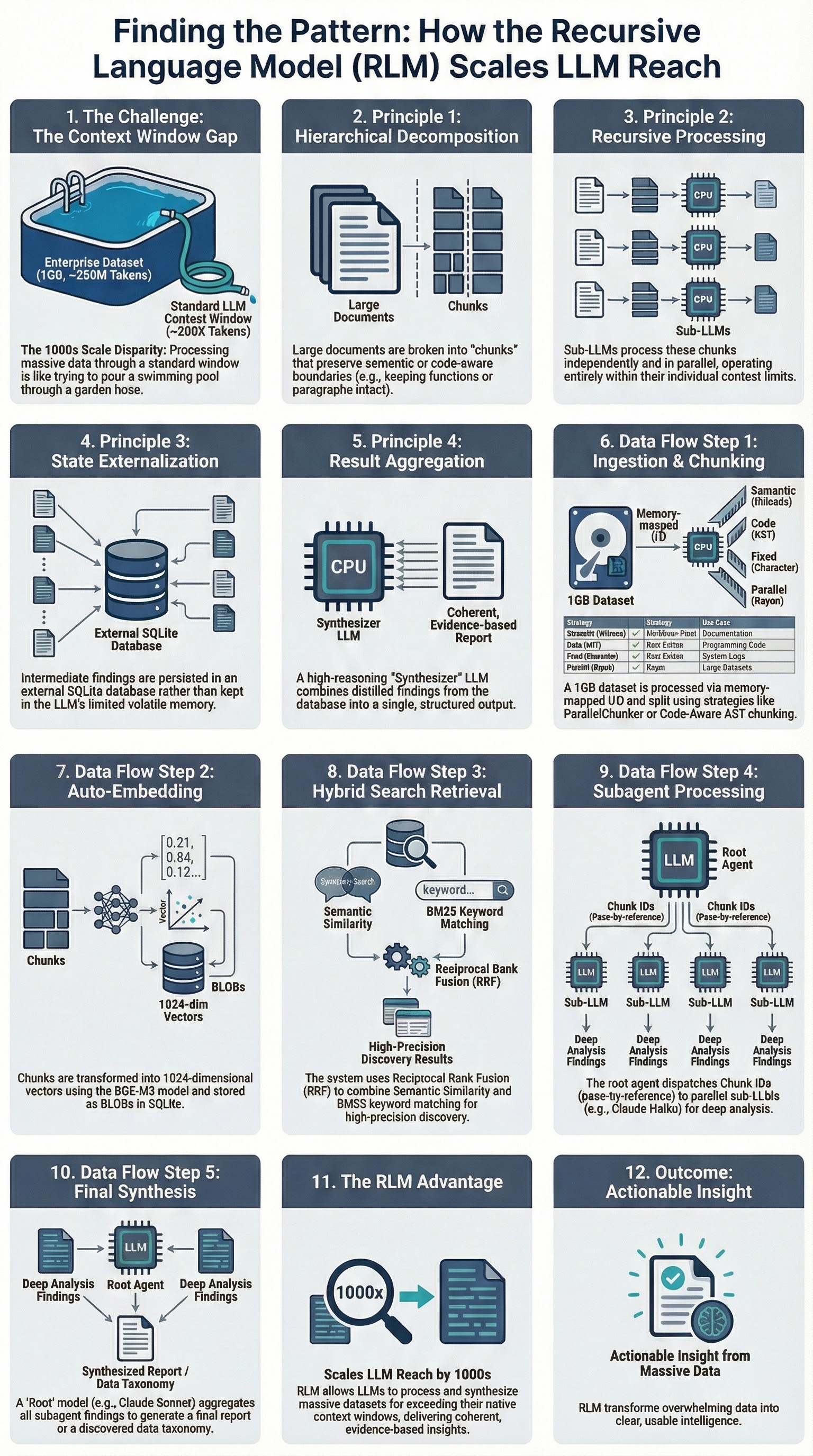
The core idea: instead of trying to fit everything into one context window, treat the input as an external environment. Let the LLM programmatically examine, decompose, and recursively call itself over manageable pieces. The paper claims RLMs can handle inputs up to two orders of magnitude beyond model context windows. Four principles make this work:
Hierarchical decomposition. Take a large document and break it into chunks that each fit comfortably in a context window. Not random splits — intelligent ones that preserve semantic boundaries. A paragraph should not be cut in half. A function definition should stay together.
Recursive processing. Each chunk gets processed independently by a sub-LLM. The sub-LLM does not need to know about the other chunks. It just does its job on the piece it was given. This is the part that scales: you can process chunks in parallel, and each sub-LLM operates within its normal context limits.
State externalization. The intermediate results from each sub-LLM get persisted outside the LLM context. In the paper this is described abstractly as an “external environment.” In practice it means a database. The LLM’s context window is not the only place information can live.
Result aggregation. A root LLM takes the sub-results and synthesizes them into a coherent final output. It does not need to see every original chunk — just the distilled findings from each one.
None of these ideas are revolutionary in isolation. Chunking text is old hat. MapReduce has been around since 2004. What the paper contributes is a formal framework for applying these ideas specifically to LLM context management, with theoretical analysis of why it works and when it breaks down.
For someone staring at a gigabyte of CSV data with a 200K-token context window, it was exactly the framework I needed.
The Rewrite
I could have used Adeojo’s Python implementation directly. I chose to rewrite it in Rust. Three reasons.
First, distribution. I manage 198 personal repositories and many more at work. When I build a tool, it needs to be a single binary I can drop on any machine. No virtualenv. No pip. No “which Python version do you have.” Rust compiles to a static binary. You copy it, you run it.
Second, performance. Processing a gigabyte of data means processing a gigabyte of data. Chunking, embedding, searching — these are compute-intensive operations on large text. Rust’s zero-cost abstractions and lack of garbage collector pauses matter when you are generating embeddings for thousands of chunks.
Third, I wanted to explore beyond the paper’s basic pattern. The paper describes the what. I wanted to build tooling that made the how practical for real workflows. That meant extending the design in ways the paper did not address.
The git history tells the story of how fast this moved. Initial commit: January 19, 2026. v0.1.0 shipped the same day — basic buffer management, chunking, variable storage. v1.0.0 the same day — semantic search, pass-by-reference chunk retrieval. v1.1.0 still the same day — hybrid search with Reciprocal Rank Fusion combining semantic embeddings and BM25 keyword matching. v1.2.0 the next day, January 20 — switched from All-MiniLM-L6-v2 to BGE-M3 embeddings, jumping from 384 to 1024 dimensions with 8192-token context per chunk. By February 8, v1.2.4 added code-aware chunking, HNSW approximate nearest neighbor search, dispatch/aggregate commands for parallel processing, and NDJSON output.
The paper’s “external environment” needed a concrete implementation. I chose SQLite — transactional reliability, single-file portability, built-in full-text search via FTS5. Every chunk, every embedding, every buffer lives in one .db file. If the process crashes mid-way, the transaction rolls back. The fastembed-rs library runs BGE-M3 embeddings natively in Rust via ONNX Runtime, so the embedding model ships inside the binary. No external API, no network dependency, no API keys. This matters when you are processing enterprise data that should not leave the local machine.
Different content needs different chunking, so I built a Chunker trait with four implementations: FixedChunker for raw text, SemanticChunker that respects sentence and paragraph boundaries, CodeChunker that splits at function and class boundaries across eight languages, and ParallelChunker using Rayon for files over 10MB.
For search, I combined semantic embeddings with BM25 keyword matching using Reciprocal Rank Fusion. Semantic search finds conceptually similar content. BM25 finds exact matches. Neither alone is sufficient. RRF combines their rankings without needing score normalization: rrf_score(d) = sum(1 / (k + rank_i(d))) across both result lists, with k=60.
The CLI is designed so any tool that can run shell commands can use it:
rlm-rs load document.csv --name data --chunker semantic
rlm-rs search "error patterns" --top-k 10 --format json
rlm-rs chunk get 42That last command — chunk get 42 — is the pass-by-reference architecture from the paper made concrete. A root LLM searches for relevant chunks, gets back chunk IDs, and hands those IDs to sub-LLMs. Each sub-LLM retrieves its assigned chunk by ID. No copying full content through the orchestration layer. The SQLite database is the single source of truth.
What Actually Happened
The enterprise support data was the first real candidate. Over 75,000 rows spanning 11 fiscal years. CSV exports from a support system for a large company. I am deliberately vague about the industry and company — the specifics do not matter for this story, and the data is not mine to identify.
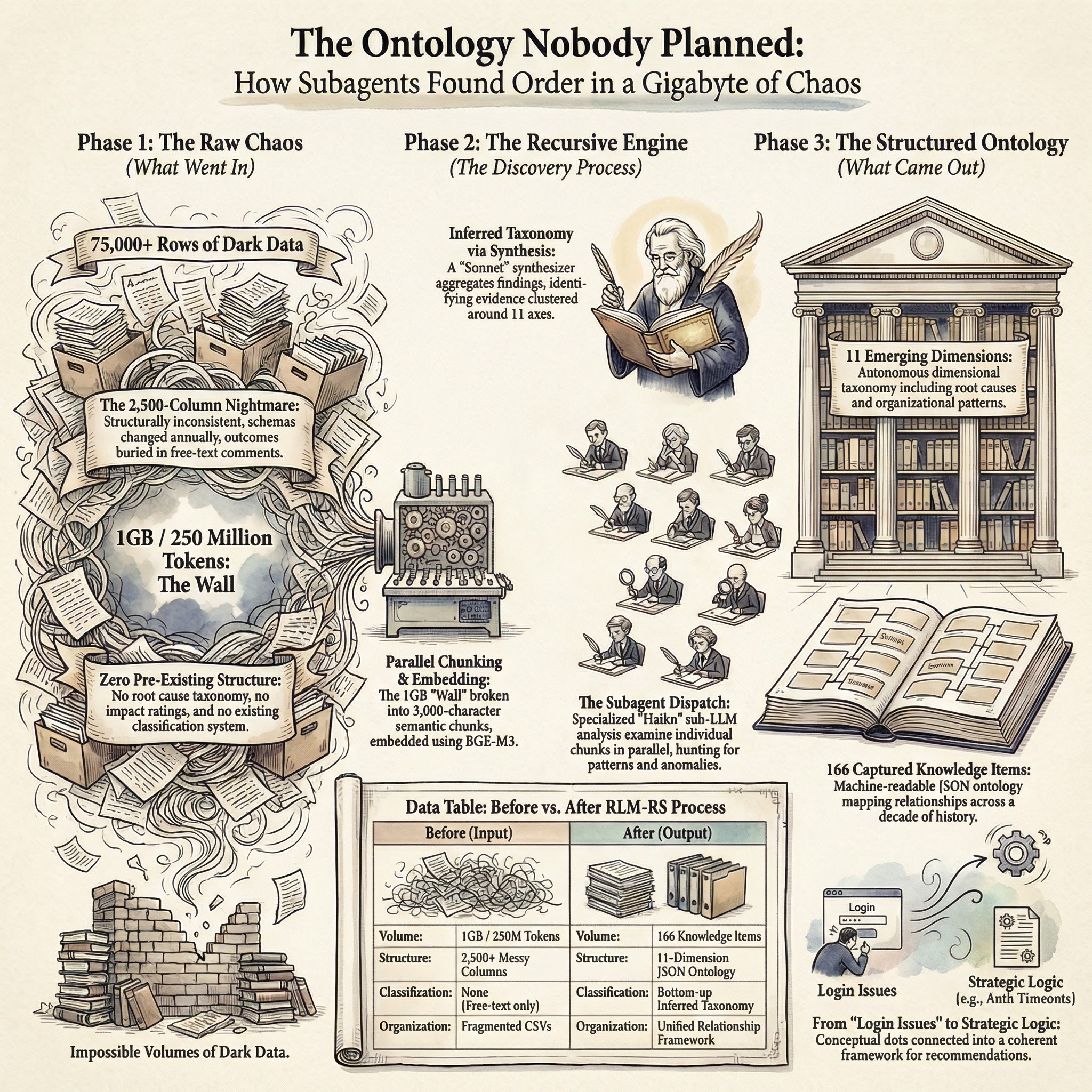
This was not clean data. The CSVs were over 2,500 columns wide in most cases. The schema was inconsistent from one fiscal year to the next — fields appeared, disappeared, got renamed. There were no clear outcome classifications beyond free-text labels and comments. No root cause taxonomy. No impact ratings. No structured categorization of what happened or why. Just years of raw ticket data with text fields that someone had typed into at the time.
The process looked like this:
Load the CSV exports into rlm-rs with semantic chunking. Each chunk gets embedded automatically on load — BGE-M3 generates 1024-dimensional vectors that get stored as BLOBs in SQLite alongside the full-text search index. The hybrid search is available immediately.
rlm-rs load fy2015-support.csv --name fy2015 --chunker semantic
rlm-rs load fy2016-support.csv --name fy2016 --chunker semantic
# ... repeat for each fiscal yearSome of the raw text files were 400MB each. The parallel chunker handled those. Memory-mapped file I/O (via memmap2) meant the full file did not need to load into RAM — the OS paged in what was needed.
Then the searches. Not simple keyword lookups. Analytical queries:
rlm-rs search "recurring failure patterns in authentication systems" --top-k 20 --format json
rlm-rs search "escalation trends across fiscal years" --mode hybrid --top-k 15The hybrid search pulled results that neither semantic-only nor keyword-only would have found. A query about “authentication failures” found chunks discussing “login issues” (semantic match) alongside chunks containing the literal string “auth timeout” (BM25 match). RRF ranked both types of results in a single merged list.
Sub-LLMs processed individual chunks via the dispatch command, which splits chunks into batches and hands them to parallel workers:
rlm-rs dispatch --query "classify support issues by root cause" --workers 4 --format ndjsonEach worker processes its batch independently. Results stream back as newline-delimited JSON. The aggregate command then combines analyst findings, deduplicates, groups by theme, and sorts by relevance.
The tool was surprisingly successful. I had expected the usual friction of a v1 tool meeting real data — format mismatches, chunks too large, search results too noisy. Some of that happened. The default chunk size was originally 240,000 characters, which was far too large for precise retrieval. I dropped it to 3,000 characters (roughly 750 tokens) in v1.1.2, and search precision improved immediately. BM25 scores in early versions displayed as 0.0000 because they were very small floating-point numbers — I added scientific notation formatting in v1.1.1.
But the core loop worked. Load data. Search data. Process chunks. Aggregate results. Repeat with refined queries. For the first time, I could ask analytical questions across 11 years of support data and get answers grounded in the actual records, not in someone’s recollection or a hand-curated summary.
The Ontology Nobody Planned
This is the section that convinced me the approach was real.
I did not set out to build a taxonomy. I loaded the data, ran analytical queries, and let the subagent system process chunks across the full dataset. The goal was straightforward: understand the data well enough to make strategic recommendations.
What came back was a dimensional taxonomy.
Remember: this data had no existing taxonomy. No root cause classifications. No impact ratings. Over 2,500 columns wide, inconsistent year to year, with outcomes buried in free-text comments that someone typed in a hurry. This was not information waiting to be read — it was information waiting to be inferred.
The subagent system — multiple analyst agents processing different chunks in parallel, with a synthesizer aggregating their findings — did not just answer the questions I asked. It discovered a classification framework in the data. Eleven dimensions emerged from pattern analysis across the 75,000+ rows. Root causes. Impact assessments. Organizational patterns. The kinds of things a proper taxonomy should capture, inferred from raw text where none of those categories had been explicitly recorded. Not imposed top-down by a human who decided what the categories should be. Discovered bottom-up from the data itself.
The system produced 166 captured knowledge items organized across 11 namespaces. Each namespace represented a dimension of the data that the analysts identified as structurally significant. Patterns in how support issues clustered. Relationships between time periods and issue types. Correlations between data fields that no one had documented.
The output was a machine-readable JSON ontology. Not a report that says “here are some trends.” An actual structured classification framework with dimensions, categories within each dimension, and relationships between them.
This mattered because it answered a question I had not asked. I asked “what patterns exist in this data?” The system answered with “here is the structure of the patterns” — a meta-answer that organized all the individual findings into a coherent framework.
To be concrete about what this looked like in practice: the synthesizer agent received findings from the data analysts, identified that findings from different chunks kept clustering around the same dimensional axes, and surfaced those axes as the taxonomy itself. When 30 different chunks across 11 fiscal years all produce findings that group into the same 11 categories, the categories are not an artifact of the analysis — they are a property of the data.
Strategic recommendations emerged from those patterns. Not “here is what the data says” but “here is what the data implies should happen next.” The recommendations were grounded in evidence from specific chunks, traceable back to specific rows in specific fiscal years.
I want to be careful about overstating this. The taxonomy was useful for this dataset. Whether the same approach would produce equally clean results on different data, I cannot say. But I also want to be clear: this was not a well-curated dataset with obvious structure waiting to be extracted. It was 2,500 columns of inconsistent, multi-year, free-text-heavy operational data with no pre-existing classification scheme. The fact that a coherent taxonomy emerged from that is what surprised me.
But 166 knowledge items across 11 dimensions, discovered bottom-up from 75,000+ rows — that was not something I could have done manually. Not in any reasonable amount of time. Not with any reasonable confidence that I had found all the patterns.
The Specialization
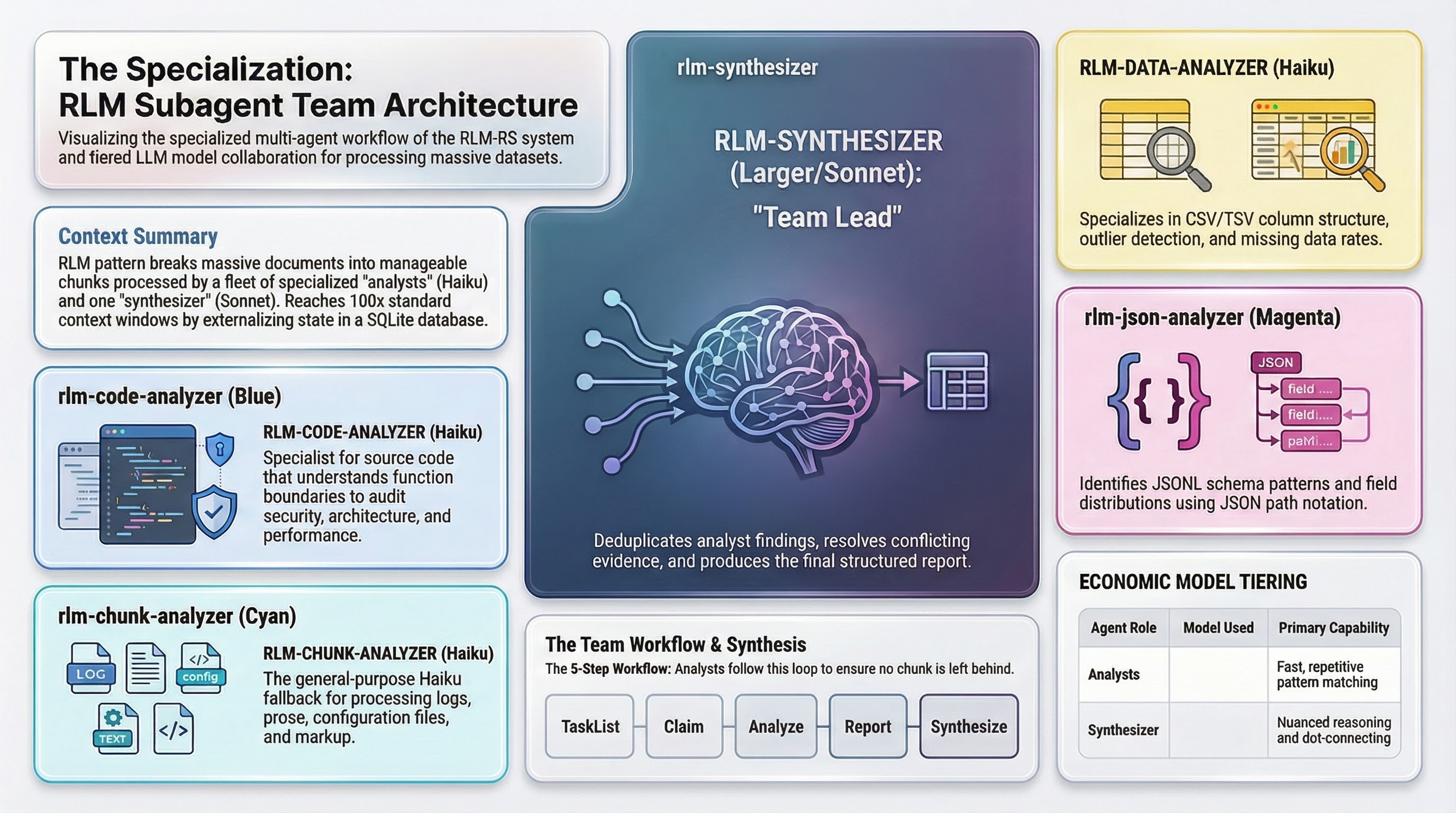
The first version of the analysis workflow used a single generic chunk analyzer. One agent prompt. One approach for every kind of data. It worked, but it was blunt.
Working through the enterprise data and then applying the same approach to operational data across my 198 personal repositories (plus more at work) made the limitations clear. CSV data has different analytical needs than JSON configuration files. Source code is not log files. The generic analyzer was adequate for all of them and excellent for none.
So I built five specialized agents. The three content-type specialists:
| Agent | Runs on | What it knows | Key capability |
|---|---|---|---|
rlm-data-analyzer | Haiku | CSV/TSV column structure | Frequency distributions, outlier detection, missing data rates — output as aggregatable JSON so the synthesizer can sum {"NA": 3200} from chunk 3 with {"NA": 2800} from chunk 7 |
rlm-json-analyzer | Haiku | JSON/JSONL schema patterns | Type inconsistency detection across records, field distributions, null frequency — uses JSON path notation ($.events[*].metadata) for precise cross-chunk merging |
rlm-chunk-analyzer | Haiku | Logs, prose, config, markup | General-purpose fallback for anything the specialists do not cover; reads by line range and tags findings with content type |
The two that needed more explanation:
The code analyzer is where specialization matters most. It understands function boundaries, class definitions, import blocks. Four analysis modes: general, security, architecture, and performance. For security, it hunts injection patterns, hardcoded secrets, unsafe deserialization. Each finding includes scope (function:process_data, class:DataProcessor) so the synthesizer can map findings back to code structure. This is what made analyzing code across 198 personal repositories (plus more at work) productive instead of noisy.
The synthesizer is the only agent that runs on a larger model (Sonnet). It receives structured findings from all the analysts, deduplicates across chunks, groups into themes, resolves conflicting evidence, and produces a structured report with chunk ID citations. The reasoning load here is genuinely different — it is not pattern matching on a single chunk but connecting dots across dozens of them.
The team workflow is explicit. Each analyst runs in a loop: check the task list for unclaimed work, claim a task, analyze the chunk, report findings, check for more work. In multi-file mode, analysts write findings directly to the task description (to avoid flooding the team lead’s context) and send only a one-line summary via message. The synthesizer reads findings from completed tasks and produces the final report.
All analyst agents run on Haiku. The synthesizer runs on Sonnet. This is deliberate economics. Chunk-level analysis is repetitive pattern matching — smaller models handle it well. Synthesis is where you need the capacity for nuanced reasoning about relationships between findings.
The specialization paid off immediately. The data analyzer catching missing data rates per column across 75,000 rows. The JSON analyzer finding type inconsistencies in configuration data that had accumulated over years. The code analyzer flagging security patterns across repositories. Each specialist found things the generic analyzer missed because it was not looking with the right lens.
The Second Implementation
Here is the part I did not expect: the RLM pattern outgrew the CLI tool that implemented it.
rlm-rs works. It does what it was designed to do. But as I used it more, I realized the bottleneck was not chunking or embedding or search. The bottleneck was orchestration. Loading data into rlm-rs, dispatching to subagents via shell commands, collecting results through files — it worked, but every step was a shell call. Every interaction between agents went through the filesystem or stdout.
Claude Code already has native primitives for multi-agent coordination: TeamCreate to spin up a team, TaskCreate to define work items, SendMessage for inter-agent communication, TaskUpdate to track progress. These are not shell commands. They are first-class tools that agents can call directly, with shared task lists, message inboxes, and lifecycle management built in.
So I built claude-team-orchestration — a Claude Code plugin that implements the RLM pattern using those native swarm primitives. No external binary. No SQLite database. No embedding step. Just markdown agent definitions and skill files that teach Claude Code how to decompose, dispatch, analyze, and synthesize.
The same five specialized agents live there: data analyzer, JSON analyzer, code analyzer, chunk analyzer, synthesizer. But instead of communicating through the filesystem, they communicate through Claude Code’s message system. Instead of claiming work by reading files, they claim tasks from a shared task list. The team lead creates a team, partitions the data, spawns analysts as teammates, and collects findings through the inbox.
The key addition was content-aware routing. The orchestrator detects the content type — CSV gets routed to the data analyzer, JSONL to the JSON analyzer, source code to the code analyzer — and applies type-specific partitioning. CSV files get split by row count (2,000 rows per chunk for narrow data, 500 for wide). Source code gets split at function boundaries. JSON arrays get split by element count. Each content type gets the chunking strategy that makes sense for it, without the user specifying anything.
This is the tool I use more frequently now. Not because rlm-rs is wrong — the approach is sound and the CLI is solid for automation pipelines and CI integration. But for interactive analysis inside Claude Code, the native swarm implementation is faster to start, has less friction per operation, and the inter-agent coordination is tighter because the agents share a real communication channel instead of passing data through shell pipes.
The pattern is the same. The paper is the same. The agents are the same five specialists. What changed is the orchestration substrate. And it turns out that matters more than I initially thought.
For the enterprise data analysis — the 75,000 rows, the ontology that emerged — I could run that same workflow today through claude-team-orchestration without touching the rlm-rs binary. TeamCreate, spawn a data analyzer per CSV chunk, collect findings via SendMessage, synthesize. The results would be the same. The path to getting them would be shorter.
Two implementations of the same pattern, optimized for different contexts. The CLI for standalone automation and CI pipelines. The swarm plugin for interactive analysis inside Claude Code. Same paper, same agents, different plumbing.
Honest Reckoning
I want to be direct about something: this may also be shiny baubles and I am suffering from parental bias. I built rlm-rs. I am invested in it working. That investment colors my assessment.
Here is what I know for certain:
The tool is at v1.2.4. It is not battle-tested software with years of production use behind it. It is months old. The CHANGELOG shows rapid iteration, which is either a sign of momentum or a sign that the design is still settling. Probably both.
Streaming input is planned but not shipped. The streaming architecture plan is thorough — four options evaluated (sync iterators, async streams, channel-based pipelines, and a hybrid approach), with the sync iterator pattern recommended as the starting point. Implementation phases are documented. File modifications are specified. None of it is implemented. The plan exists as streaming-plan.md, not as code.
The embedding model switch from All-MiniLM-L6-v2 to BGE-M3 in v1.2.0 was a breaking change that required regenerating all existing embeddings. Schema migration v3 handles this automatically, but it is a reminder that the tool is still finding its final shape. Users who had embedded large datasets had to re-embed.
The HNSW vector index is behind a feature flag (usearch-hnsw). It is there because brute-force cosine similarity does not scale indefinitely. But the initial release had a segfault in the usearch integration that required a move semantics fix in v1.2.4. The feature works now, but the fact that it shipped with a memory safety issue in a Rust project tells you something about the maturity level of that integration.
What I can say honestly: I have not come up with a better process to parse so much raw information and make legible sense and work of it until now. Before rlm-rs, my options were: read the data manually (impossible at this scale), write one-off scripts for specific queries (slow, non-reusable), or dump everything into an LLM and hope (context window says no). The RLM pattern gave me a fourth option that actually works. Whether it works because the approach is sound or because I got lucky with a well-structured dataset, I cannot fully distinguish.
The 166 knowledge items and 11-dimension taxonomy from the enterprise data analysis — that result is real. Those items exist. The taxonomy emerged from the data. But I have not yet run the same process on a dataset where I already know the ground truth, so I cannot rigorously validate the accuracy. The findings looked right. The strategic recommendations made sense. That is not the same as proving they are correct.
The Takeaway
LLMs can do real analytical work at scale. But only with scaffolding.
The raw intelligence is there. A model that can analyze a 3,000-character chunk of support data and identify patterns, outliers, and anomalies is genuinely useful. The problem was never the model’s capability on any single chunk. The problem was reach — getting the model’s attention to touch every part of a dataset that is a thousand times larger than its context window.
The RLM pattern provides the scaffolding. Zhang, Kraska, and Khattab (2025) gave the theory: decompose, process recursively, externalize state, aggregate results. Adeojo’s Python implementation proved it worked in practice. The Rust rewrite gave me a single binary with embedded embeddings, transactional storage, and hybrid search that I could run against a gigabyte of data without external dependencies.
The specialized agents gave the precision. A generic “analyze this chunk” prompt produces generic findings. A CSV-aware analyst that counts column distributions and detects missing data rates produces findings that can be aggregated numerically across chunks. A code-aware analyst that understands function boundaries and import patterns produces findings that map to architecture. Specialization is what turned “process chunks in parallel” from a MapReduce exercise into actual analysis.
And the data gave the validation.
75,000+ rows of enterprise support data spanning 11 fiscal years. One gigabyte. A dimensional taxonomy with 11 dimensions that nobody planned and nobody imposed. 166 captured knowledge items organized into a machine-readable ontology. Strategic recommendations grounded in evidence from specific records in specific time periods.
The taxonomy is the thing that convinced me. Not the tool itself — the result. The system discovered structure in the data that no human had catalogued. That is not a feature demo. That is a result.
I built rlm-rs because I had data that mattered and no way to make an LLM work through it. The paper said the approach should work. The implementation let me test whether it did. And the ontology that emerged from 75,000 rows told me it did.
Whether that answer holds for every dataset and every domain, I do not know. For this one, it held. And I have not found a better process yet.
rlm-rs is open source under the MIT license: github.com/zircote/rlm-rs
claude-team-orchestration is open source under the MIT license: github.com/zircote/claude-team-orchestration
The original research paper: Zhang, A. L., Kraska, T., & Khattab, O. (2025). Recursive Language Models. arXiv:2512.24601
The Python implementation that started it: github.com/brainqub3/claude_code_RLM by John Adeojo