CLI Error Messages Are a Dual-Consumer Problem in 2026
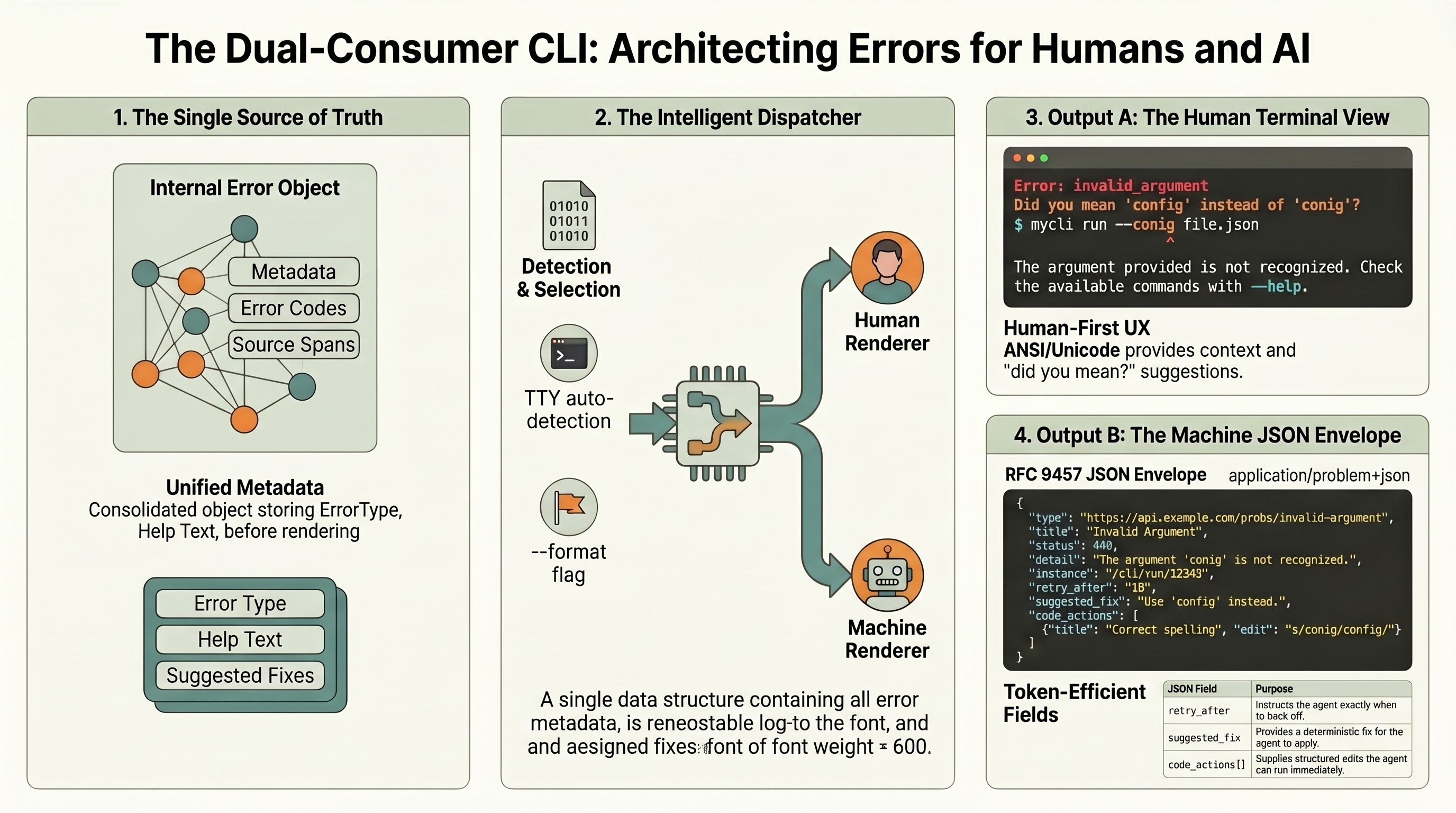
Command-line tools now answer to two distinct audiences. The first is the human who ran the command and is reading the terminal. The second is the language-model agent that orchestrated the command, is parsing the bytes, and will decide whether to retry, escalate, or abandon. Most CLI error messages serve the first audience adequately and the second audience poorly. That imbalance is not a polish problem. It is a cost problem, a reliability problem, and a convergence problem, and each of those has a concrete fix available in 2026.
This article walks through three of those fixes. The argument is bottom-line first for each:
- Verbose human-formatted tracebacks in
tool_resultblocks are billing you for every agent retry. Structured JSON output closes that leak. - RFC 9457 Problem Details, written for HTTP, is a credible transport envelope for CLI errors and lowers coordination cost across the ecosystem.
- Agents need remediation declared, not inferred. A three-field extension (
retry_after,suggested_fix,code_actions[]) is the smallest change with the largest reliability payoff.
1. Why Your CLI’s Error Messages Are Costing You Tokens

The hidden floor on Anthropic’s tool use is higher than most CLI authors expect. Claude Opus 4.6 and Sonnet 4.6 prepend a tool-use system prompt that costs between 313 and 346 tokens per request, depending on tool_choice. Every tool_use block and every tool_result block in the conversation history counts as input tokens on each subsequent turn. An error surfaced through a CLI is not a free diagnostic event. It is an input-token transaction that repeats for every iteration the agent takes before the loop converges.
Consider a realistic scenario. A build tool exits non-zero and your tool wrapper pipes both stdout and stderr into a tool_result content block. The rendered output resembles this:
error: linking with `cc` failed: exit status: 1
|
= note: LC_ALL="C" PATH="/home/user/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/bin:..." \
VSLANG="1033" "cc" "-m64" "/tmp/rustcQf8z3k/symbols.o" "/workspace/project/target/debug/deps/project-abc123.project.xxx.rcgu.o" \
"/workspace/project/target/debug/deps/project-abc123.project.yyy.rcgu.o" [... 87 more args ...]
= note: /usr/bin/ld: cannot find -lssl: No such file or directory
/usr/bin/ld: cannot find -lcrypto: No such file or directory
collect2: error: ld returned 1 exit status
error: could not compile `project` (bin "project") due to 1 previous errorThat is approximately 5 kilobytes of text (a reasonable traceback for a failed link), which tokenizes to roughly 1,250 input tokens. Add the 313-to-346-token tool-use floor, and a single failed command consumes around 1,600 tokens before the model does any reasoning. The agent reads the output, concludes the system is missing OpenSSL development headers, and proposes installing libssl-dev. The install succeeds. The build is re-invoked. That is two tool turns, two tool_result blocks billed into the next model turn, and a running cost near 3,000 input tokens for one retry.
Now multiply. An agent debugging a flaky integration test may iterate ten or fifteen times. A heavy-handed traceback becomes the dominant line item on the invoice. This is not a hypothetical. Anthropic’s own documentation states that tool_use content blocks in API requests and responses, and tool_result content blocks in API requests, all count toward tokens.
The alternative is already shipping. Miette, the Rust diagnostic library, extends std::error::Error with a Diagnostic trait carrying code, help, severity, url, labels, source_code, and related fields. It ships two renderers: a fancy ANSI/Unicode terminal report for humans, and a JSONReportHandler for machine consumption. The NarratableReportHandler is auto-selected in non-graphical environments (CI runners, screen readers, NO_COLOR). The derive macro #[derive(Diagnostic)] composes with thiserror, so adoption is ergonomic rather than invasive.
A miette JSON rendering of the same link failure looks roughly like this:
{
"code": "rustc::linker_error",
"severity": "error",
"message": "linking with cc failed",
"help": "install libssl-dev and libcrypto, then re-run",
"labels": [
{"span": {"offset": 0, "length": 0}, "label": "ld cannot find -lssl"},
{"span": {"offset": 0, "length": 0}, "label": "ld cannot find -lcrypto"}
],
"related": [{"code": "E0463", "message": "could not compile project"}]
}That payload is approximately 350 bytes. It tokenizes to roughly 90 input tokens. The same failed command now costs 313 (tool-use floor) plus 90 (error payload), which is 403 tokens. Compared with the 1,600-token verbose version, that is a 75 percent reduction per tool_result. Across fifteen retry iterations, the savings compound to tens of thousands of tokens. On Claude Opus 4.6 input pricing, that is real money per agent session.
A back-of-envelope cost model, then:
cost_per_retry = (tool_floor + tool_result_bytes / bytes_per_token) * input_price_per_token
tool_floor = 313 to 346 for Claude 4.x tool use (Anthropic documentation)
bytes_per_token ≈ 4 (conservative for English text)If you are building a CLI that agents will consume, the question is no longer whether to support a machine-readable error format. The question is which format, and what that format should contain. The answer to both follows in the next two sections.
One caveat worth stating plainly. The token savings apply to the payload the agent sees. They do not apply to the terminal experience for humans. A dual-format CLI ships both renderings in the same binary and selects between them based on an explicit flag (--format=json or --format=pretty) or on TTY detection. The human rendering remains as lush as it ever was. The agent gets the structured version. Neither audience is asked to compromise on the other’s behalf.
2. The Case for RFC 9457 as a CLI Convention

RFC 9457 Problem Details was published in July 2023 and supersedes RFC 7807. It was written for HTTP APIs, but the envelope it defines is transport-neutral and portable to CLI use with minimal friction. The specification defines five standard members. All are optional, with defined defaults and semantics when present:
type: a URI reference identifying the problem type. Default isabout:blank. This is the machine-dispatchable key.title: a short, human-readable summary of the problem type. One sentence.status: a JSON number. In HTTP it carries the response status code. In CLI context, it maps to the process exit code or a status class.detail: a human-readable explanation specific to this occurrence. One to three sentences.instance: a URI reference identifying the specific occurrence. This is the correlation handle for logs, traces, and support tickets.
Section 3.2 of the RFC permits extension members (for example, an errors array with JSON Pointer locations into the offending input). Clients MUST ignore unrecognized extensions. The registered media type is application/problem+json, with application/problem+xml as a parallel XML form.
Five objections tend to appear when someone proposes RFC 9457 for CLI use. Each has a direct answer.
Objection 1: HTTP status codes do not map to CLI exit codes. True in the absolute sense, and irrelevant in practice. The status field is documented as advisory even in HTTP contexts. A CLI can adopt its own status-number scheme (for example, 4xx for user-input errors, 5xx for environment or upstream failures, reserving the numeric space to mirror HTTP semantics for developer familiarity). Alternatively, a CLI extension can add a exit_code field alongside status. The envelope does not mandate HTTP semantics. It mandates that a number sit in that slot.
Objection 2: The type URI is awkward for CLI authors. Not really. The URI does not need to resolve. about:blank is the default. Most CLIs will publish types at stable paths under their own documentation domain (for example, https://docs.example.com/cli/errors/missing-config). The agent side wins immediately: a stable URI is a stable dispatch key. No string-matching brittleness, no i18n drift, no pattern churn across versions.
Objection 3: RFC 9457 is for web APIs. The specification is for structured error communication between machines over JSON. HTTP is the first adopter, not the last. The envelope composes cleanly over any byte stream (stderr, a JSON-RPC response, a Pub/Sub event). A reasonable forecast: RFC 9457 becomes the dominant schema for CLIs that wrap HTTP APIs (stripe, cloudflare, aws, gh), SARIF remains dominant for static-analysis output, and rustc-style bespoke diagnostic schemas persist for compilers because they need span and label richness neither envelope expresses cleanly. That is not one winner but three, organized by domain. An HTTP-wrapping or API-wrapping CLI has the cleanest fit.
Objection 4: SARIF is richer. It is, for static-analysis output. SARIF 2.1.0 defines sarifLog -> runs[] -> results[] with rule metadata, multi-location information, code flows, fix objects, and artifact change sets. For a linter, SARIF is the right tool. For a generic CLI that wants to tell an agent “this failed, here is why, here is what to try next,” SARIF is heavier than necessary and more complex to emit. RFC 9457 is the minimal viable envelope. SARIF is the richer envelope for a specific job. They coexist by design.
Objection 5: We already have an ad-hoc format. Most CLIs do. The cost of ad-hoc is paid at the agent boundary: every new CLI requires a new parser, a new taxonomy of error strings, a new retry policy. Convergence on RFC 9457 as the baseline (with domain-specific extensions) reduces that cost to near zero. An agent runtime that understands application/problem+json understands every CLI that emits it, without per-tool adapters.
A worked mapping from a build error to RFC 9457:
{
"type": "https://docs.example.com/cli/errors/linker-missing-library",
"title": "Linker cannot find a required system library",
"status": 471,
"detail": "ld failed: cannot find -lssl. The OpenSSL development headers are not installed on this system.",
"instance": "urn:build:f9e4c2b1-a3d5-4e7f-9b8c-1d2e3f4a5b6c",
"exit_code": 1,
"libraries_missing": ["ssl", "crypto"],
"suggested_fix": "Install libssl-dev (Debian/Ubuntu) or openssl-devel (RHEL/Fedora), then re-run the build.",
"docs_url": "https://docs.example.com/cli/errors/linker-missing-library"
}Three of those fields (libraries_missing, suggested_fix, docs_url) are extension members. Any client that does not understand them ignores them and still has a valid Problem Details object. That is the extension mechanism working as designed.
The convergence argument is stronger than any single adoption case. A CLI that emits application/problem+json is legible to every agent, every test harness, every monitoring pipeline, and every human tool author who has ever written a REST client. That is a lot of existing muscle memory to pick up for free. The cost is a small shim in the CLI that renders the same internal error object twice: once to a human-readable terminal view, once to application/problem+json on --format=json. The dual renderer is already a solved pattern in miette, rustc, and Ruff. RFC 9457 plus a dual renderer is perhaps four hundred lines of code for a new Rust CLI, and less for Python or Go CLIs that can reuse existing problem+json crates.
Two caveats worth naming explicitly. First, RFC 9457 does not cover streaming or multi-error aggregation as elegantly as SARIF does. If a single CLI invocation produces twenty distinct errors (a linter run, a batch validator), consider an errors[] extension member with per-error Problem Details objects, or emit JSON Lines with one Problem Details object per line. Second, type URIs need governance. A CLI author must commit to stable URI paths and a versioning policy (either the URI embeds a version, or the problem-type documentation tracks a changelog). Agents will cache mappings from type URIs to recovery strategies, and breaking those mappings silently is worse than not providing them.
3. Remediation Fields: What LLMs Need That Humans Do Not
![The remediation trio: retry_after (seconds or ISO 8601, declarative retry directive sourced from RFC 7231 §7.1.3), suggested_fix (free-text or structured action, rustc precedent with machine_applicable/has_placeholders/maybe_incorrect/unspecified applicability gate), and code_actions[] (structured edits modeled on LSP CodeAction)](/assets/images/posts/2026-04-15-cli-error-messages-are-a-dual-consumer-problem/remediation-trio.png)
Humans infer. Agents declare, retry, or abandon. The gap between those two behaviors is where most agent-CLI failure lives today.
Consider two equivalent error events. First, the human-optimized version:
Error: Rate limit exceeded. Please wait and try again.A human reads that, glances at the clock, leaves the terminal, and comes back five minutes later. The loop closes. Second, the agent’s experience of the same error:
Error: Rate limit exceeded. Please wait and try again.The agent sees the same string. The ReAct loop runs: the model reads the error, reasons “I should wait and retry,” emits a new tool_use block almost immediately, and hits the same rate limit. Some model responses will abandon the task entirely. Published reliability research documents the pattern in plain terms: rate-limit errors cause agents to abandon tasks rather than retry. The human gets a hint. The agent gets the same hint and cannot act on it because the hint omits the one thing the agent needs, which is a number.
A small extension to the Problem Details envelope closes most of that gap. Three optional fields carry their weight:
retry_after: a delta-seconds number or a timestamp indicating when the operation may safely be retried. The HTTP world has known this since RFC 7231 (Section 7.1.3), which defines Retry-After as either delta-seconds or an HTTP-date. A CLI can port the HTTP semantic directly, or accept ISO 8601 as a CLI-specific extension for ergonomics. Either way, the agent scheduler has a declarative directive it can consume. No reasoning hop. No guess. The value is the value, and the wait is the wait.
suggested_fix: a free-text or structured description of the recovery action. Rust’s rustc has shipped this pattern for years: diagnostics carry help: and suggested_replacement fields with Applicability markers (machine_applicable, has_placeholders, maybe_incorrect, unspecified). An agent that sees "applicability": "machine_applicable" can edit and retry without a confirmation step. An agent that sees "applicability": "maybe_incorrect" knows to escalate to the human. The machine-applicable suggestion is load-bearing; the applicability marker is the safety gate.
code_actions[]: a list of structured edits modeled on the LSP CodeAction interface. Each action has a title, a kind (for example quickfix), an edit payload (textual changes with locations), and an optional isPreferred flag. LSP’s Diagnostic interface pairs with CodeAction precisely because the diagnostic tells you what is wrong and the action tells you how to fix it. Bringing that same split to CLI output lets an agent accept a fix in one turn rather than reasoning through a three-turn “read error, write patch, apply patch” sequence.
Research on agent failure modes backs this up directly. A 12-category tool-invocation framework in the recent agent-reliability literature distinguishes “result interpretation” failures from parameter failures. An error that names the failure but omits the fix produces a common anti-pattern: correct diagnosis followed by wrong action. The agent reasoned about the error, picked a plausible-looking fix, and applied something the system was not asking for. Structured remediation eliminates the reasoning hop entirely.
This convergence is best read as plausible rather than inevitable. Three optional fields (retry_after, suggested_fix, docs_url) are the candidate baseline. The signal worth watching: whether Claude Code, Cursor, and OpenAI’s tool-use SDK align on a shared convention or ship competing ones. The refuting signal is a major agent runtime publishing an incompatible extension. The confirming signal is an IETF or OpenAPI registry entry for an agent-oriented problem type.
Put crudely, humans read this:
Error: Rate limit exceeded. Please wait and try again.Agents should read this:
{
"type": "https://api.example.com/errors/rate-limit-exceeded",
"title": "Rate limit exceeded",
"status": 429,
"detail": "You have exceeded the rate limit for this endpoint. Retry after the indicated interval.",
"instance": "urn:request:2026-04-15T14:22:10Z-req-abc123",
"exit_code": 2,
"retry_after": 180,
"suggested_fix": "Wait 180 seconds before retrying. Consider reducing batch size or increasing concurrency limits.",
"docs_url": "https://api.example.com/docs/rate-limits"
}Both audiences are now served. The human still sees the pretty terminal output. The agent sees a number, a suggested action, and a pointer to documentation. Neither is asked to parse the other’s view. The CLI does that work once, in the dual renderer, at emission time.
One design choice worth flagging. The suggested_fix field can be free text or structured. A free-text field is easier to emit and harder to consume programmatically. A structured field (for example, {"action": "install_package", "package": "libssl-dev", "manager": "apt"}) is more rigorous but requires agreement on action schemas. A pragmatic middle ground: ship suggested_fix as free text in the first version, and add code_actions[] as structured edits when the recovery is code-shaped rather than environment-shaped. The two fields compose. An agent should prefer code_actions[] when present and fall back to suggested_fix otherwise.
How These Three Fixes Compose
The three sections above are not independent. They compose into a small, implementable specification:
- Emit errors as RFC 9457 Problem Details JSON on
--format=jsonor when stdout is not a TTY and the caller has opted into machine output. This is the transport envelope. - Ship a dual renderer. The same internal error object produces a human-readable terminal view with spans, color, and help text, and a machine-readable
application/problem+jsonoutput with stable keys. Miette is the reference implementation for Rust. Rich serves the same role in Python. Neither binds you to a framework. - Add three extension members:
retry_after,suggested_fix, anddocs_url. Optionally shipcode_actions[]for edit-shaped fixes, modeled on LSP’sCodeAction. These are the agent-oriented fields.
Implementation cost for a small CLI is modest. The Rust ecosystem has miette plus a problem-details crate as a foundation. The Python ecosystem has Click or Typer plus Rich plus a Problem Details library. The Go ecosystem has Cobra plus any encoding/json-based emitter. The pattern is transferable. The hard part is not the code. The hard part is committing to stable type URIs and a versioning policy, and that is a governance question, not a technical one.
The token economics in Section 1 alone make the ROI visible on any CLI that agents actually use. The convergence argument in Section 2 makes it visible to any CLI author who would rather inherit muscle memory than build a new taxonomy. The reliability argument in Section 3 makes it visible to anyone who has watched an agent fail to retry a 429 and abandon a task that was three seconds away from succeeding.
CLIs have always had to choose between terse and verbose, machine-readable and human-readable, clever and dumb. The choice used to be binary. It is no longer. The infrastructure to serve both audiences from the same binary exists today, costs little to adopt, and pays back at every retry. A CLI built in 2026 that does not emit structured errors is leaving tokens, reliability, and agent-ergonomic wins on the table.
Sources
- RFC 9457 (Problem Details for HTTP APIs): rfc-editor.org/rfc/rfc9457.html
- RFC 7231 Section 7.1.3 (Retry-After header): datatracker.ietf.org/doc/html/rfc7231#section-7.1.3
- SARIF 2.1.0 (OASIS Standard): docs.oasis-open.org/sarif/sarif/v2.1.0/sarif-v2.1.0.html
- LSP 3.17 Specification (Diagnostic and CodeAction): microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/
- Anthropic tool-use documentation (tool-use system-prompt token cost): platform.claude.com/docs/en/docs/agents-and-tools/tool-use/overview
- miette documentation: docs.rs/miette
- rustc diagnostic guide: rustc-dev-guide.rust-lang.org/diagnostics.html
- clig.dev (Command Line Interface Guidelines): clig.dev
- MCP specification: modelcontextprotocol.io
- Agent reliability research (rate-limit abandonment): arxiv.org/html/2601.06112v1
- Tool-invocation failure taxonomy: arxiv.org/abs/2601.16280