Why Enterprise AI Agents Route on Intuition Instead of Knowledge
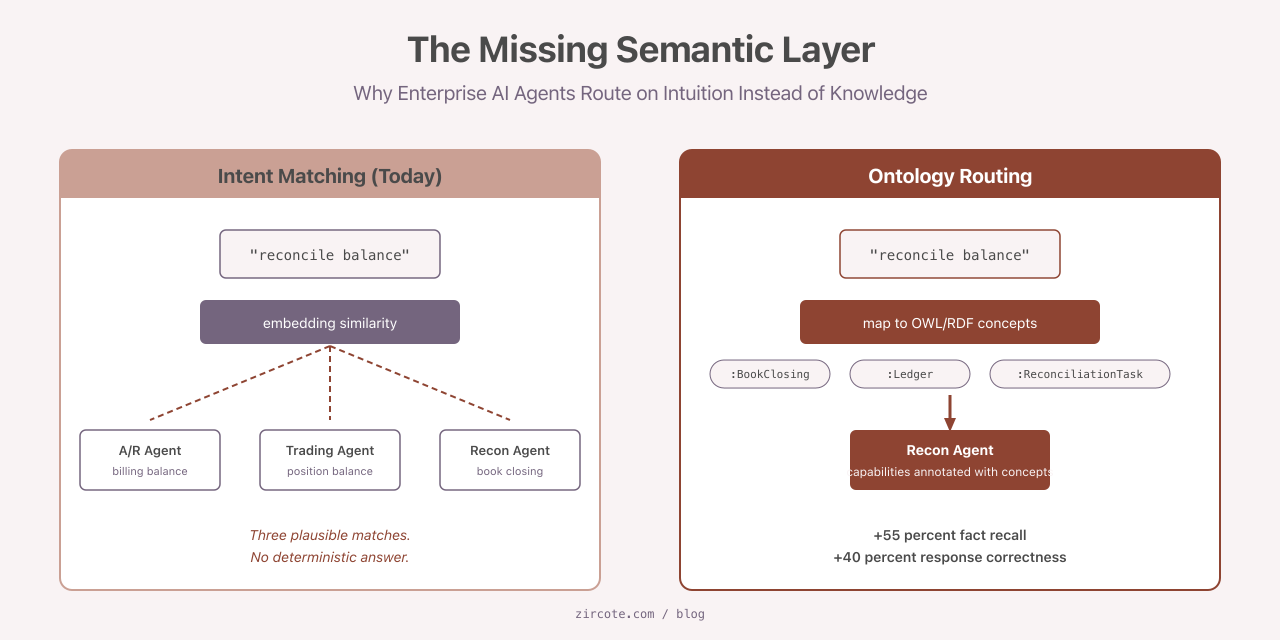
Most enterprise multi-agent systems route work the same way a search engine routes queries: by similarity. The orchestrator embeds the task, embeds the agent descriptions, picks the closest match, and dispatches. This works in demos. It fails quietly in production, because the word “customer” in the CRM does not mean what “customer” means in billing, and neither matches what compliance calls a customer. The agents do their jobs. The jobs are the wrong ones.
The fix is not better embeddings. The fix is a formal semantic layer: an ontology, expressed in OWL or RDF (Web Ontology Language and Resource Description Framework, the W3C standards for machine-readable semantics), that the orchestrator can reason against before it picks an agent. The published evidence for that claim is now substantial. The numbers are large enough to take seriously: 55 percent better fact recall, 40 percent improvement in response correctness, and a reported 64 percent adoption rate of standardized ontology languages across surveyed multi-agent systems.
What follows explains why intent matching breaks at scale, what ontology-grounded routing replaces it with, and the three concrete patterns teams are using to deliver semantic context to agents at runtime.
Why Intent Matching Fails Quietly
Embedding similarity is the wrong tool for routing across heterogeneous business domains, and the failure mode is invisible.
Consider a request that arrives at an orchestrator: “reconcile the open balance for account 47821.” Three agents could plausibly handle it. An accounts-receivable agent owns billing balances. A trading-desk agent owns position balances. A reconciliation agent owns end-of-day book closings. All three agent descriptions contain the words “balance” and “account.” The cosine similarity is roughly the same for each. The orchestrator picks one, and the picked agent confidently produces an answer using the wrong ledger.
There is no error message. The output looks right. The cost surfaces three weeks later when an auditor reviews the reconciliation log.
Three failure modes drive this pattern:
- Semantic inconsistency. The same business term resolves to different entities across systems. Embeddings cannot distinguish them, because embeddings encode language, not organizational meaning.
- Rule fragmentation. Business rules (“a customer in default cannot place new orders”) live in code comments, runbooks, and tribal memory. No shared formal model exists, so agents apply contradictory versions.
- Context deficiency. Agents act without organizational grounding. They know the prompt and the tool schema. They do not know who the actor is, what permissions apply, or which downstream systems must be consistent.
A semantic layer addresses all three by making the meanings, the rules, and the context queryable rather than implicit.
Routing as a Mapping Problem, Not a Search Problem
The architectural shift is to treat the ontology as the control layer, not as enrichment.
In an ontology-grounded orchestrator, agent capabilities are annotated with formal concepts from a domain ontology. When a task arrives, the orchestrator does not ask “which agent description is closest to this request.” It maps the request to ontology concepts, then queries the capability catalog for agents whose capability annotations match those concepts. Routing becomes deterministic. The same input produces the same routing decision, every time, with an audit trail that names the concepts involved.
Salesforce describes this in its Agentic Enterprise Architecture as a “Composable Capability Catalog.” Every resource (agent, tool, data product) carries semantic metadata referencing a shared ontology. Discovery is composition, not similarity. HiveMQ takes the pattern further in industrial IoT deployments: the ontology defines machines, operators, materials, their relationships, and the actions permitted within a given operational context. The ontology functions as the policy layer at the same time it functions as the routing layer. A wrong action is not blocked by a guardrail after the fact; it is unreachable, because no agent has the semantic capability to perform it.
The practical consequence for architects is that the question shifts from “which agent should handle this” to “what concepts does this task touch, and which agents are authorized over those concepts.” The shift is small in code. It is large in determinism.
Programmatic Context, Not Documentation
Once routing places a task with the correct agent, the agent needs organizational grounding. The wrong way to do this is to inject a fifty-page domain glossary into the system prompt. The right way involves three runtime patterns, each suited to different ontology sizes and latency budgets.
Tool-use queries. The agent receives a query_kg() tool that accepts SPARQL or Cypher and returns structured results from the knowledge graph at inference time. This pattern is best for precise lookups against well-structured domains where the agent needs to retrieve a specific fact (the regulatory class of a chemical, the account hierarchy for a customer, the upstream dependencies of a service). Latency is non-trivial; cache aggressively.
Ontology-informed system prompts. A scoped fragment of the ontology (the agent’s identity, its permissions, the vocabulary it operates over) is rendered into the system prompt at session start. This pattern is fast, requires no runtime queries, and works well when the agent’s scope is narrow enough that the relevant ontology subset fits in context.
Embedding plus ontology-grounded RAG. For ontologies too large to inject and too query-heavy to traverse on every turn, schema definitions are embedded into vector space and retrieved by similarity. The ontology constrains what gets embedded and how chunks are grouped, which is the key difference from naive RAG.
Mature deployments use all three. Routing reads the ontology; the agent prompt carries the small grounding fragment; the agent calls query_kg() for specific lookups; and a RAG layer covers the long tail of background knowledge. Each pattern earns its place by what it makes faster, and none of them require a “fifty-page PDF” approach.
OG-RAG: The Empirical Case for Ontology-Grounded Retrieval
The strongest empirical evidence for ontology grounding comes from OG-RAG (Ontology-Grounded Retrieval-Augmented Generation), published at EMNLP 2025 by Microsoft Research (arXiv:2412.15235; reference implementation at github.com/microsoft/ograg2).
Standard RAG retrieves text chunks by embedding similarity. OG-RAG anchors retrieval in a domain ontology by constructing hypergraph representations where each hyperedge encapsulates a cluster of facts grouped by ontological relationship. Retrieval returns clusters, not isolated chunks, and those clusters preserve the relationships that the agent needs in order to reason.
Across four large language models and several domains, the reported gains are:
| Metric | Improvement vs. baseline RAG |
|---|---|
| Accurate fact recall | +55 percent |
| Response correctness | +40 percent |
| Attribution speed | +30 percent |
| Fact-based reasoning accuracy | +27 percent |
Two caveats are worth stating. First, these results assume a domain that already has predefined rules and procedures: healthcare, legal, agriculture, journalism, regulated finance. In domains where the rules are themselves emergent, the lift will be smaller. Second, ontology construction is a real upfront cost. The 55 percent recall gain is not free; it pays for the work of formalizing the domain.
That said, in any regulated or rule-driven domain, the math is straightforward. If retrieval is the dominant correctness lever (and in agentic systems with tool-use, it usually is), a 55 percent recall improvement compounds across every downstream step.
Coordination: The Blackboard Pattern Returns
Individual agent grounding is one problem. Keeping a swarm of agents semantically aligned is a different problem.
The blackboard architecture, originally proposed by Hayes-Roth in 1985, has been adapted for LLM-based multi-agent systems as bMAS (arXiv:2507.01701). A shared memory space replaces individual agent memory. Public and private partitions divide what is broadcast from what is held locally. An LLM-based control unit picks which agents act each round, based on the current blackboard state. Specialized roles (planner, decider, critic, cleaner, conflict-resolver) interact through the shared semantic surface rather than through point-to-point messages.
On the MATH benchmark the reported numbers are 72.60 percent accuracy at roughly 4.7 million tokens, against 70.20 percent at 5.5 million-plus tokens for static coordination graphs. Better accuracy at lower token cost. The same survey reports that 64 percent of multi-agent systems now employ standardized ontology languages (predominantly OWL and RDF) for the shared semantic framework that the blackboard depends on.
The pattern is not new. The relevant observation is that the field has rediscovered why the original blackboard design was useful: when many specialists need to share context without exploding the message graph, a shared semantic surface beats peer-to-peer coordination. LLM agents are specialists, and the failure mode of unbounded peer-to-peer messaging is well documented in production.
A Practical Implementation Sequence
The research points to an order of operations that delivers value early.
- Annotate agent capabilities with domain concepts. Even a small OWL or RDF vocabulary covering the top twenty business entities reduces misrouting in production. The Composable Capability Catalog pattern is a useful template; capability annotations live next to the agent definition, not in a separate document.
- Add a
query_kg()tool. Expose the knowledge graph through SPARQL or Cypher behind a single tool surface. Keep the schema small at first. The point is that agents can interrogate organizational state at runtime, not that the graph is comprehensive on day one. - Adopt OG-RAG where the domain has rules. If the agents operate in a regulated, procedural, or otherwise rule-heavy environment, replace baseline RAG with an ontology-grounded variant. The reference implementation lowers the activation cost; the upfront investment is in the ontology, not the retrieval code.
- Adopt blackboard coordination once a third agent appears. Two agents can talk peer-to-peer. Three or more start producing the messaging-graph problems that bMAS was designed to solve. Move to a shared semantic surface before the message volume forces it.
None of these steps requires a full enterprise ontology to start. They require a small, honest model of the domain, expressed in a standard language, treated as production infrastructure rather than research output.
What This Means for Practitioners
Ontologies are not a research luxury. They are the mechanism by which agents acquire organizational grounding, and the production evidence is now sufficient to warrant treating them as a first-class architectural concern.
Without a semantic layer, agents reason on intuition. They will continue to look correct in demos and quietly fail in production, with the failures distributed widely enough that no single incident triggers a redesign. With a semantic layer, agents reason on knowledge: routing becomes deterministic, retrieval becomes domain-aware, and coordination becomes auditable.
The work is not glamorous. It looks like data modeling. The payoff is that the agents stop guessing.
If your organization is shipping multi-agent systems and the routing layer still relies on embedding similarity, the next architectural decision is whether to formalize the domain or pay the integration cost in production failures. The published research, the open-source implementations, and the production deployments at major vendors all point in the same direction.
References
- Microsoft Research. OG-RAG: Ontology-Grounded Retrieval-Augmented Generation for Large Language Models. arXiv:2412.15235. https://arxiv.org/abs/2412.15235
- Microsoft. ograg2 reference implementation. https://github.com/microsoft/ograg2
- A Blackboard Architecture for Multi-Agent Systems with Large Language Models. arXiv:2507.01701. https://arxiv.org/abs/2507.01701
- Hayes-Roth, B. A blackboard architecture for control. Artificial Intelligence, 26(3), 1985.
- Salesforce. Agentic Enterprise IT Architecture. https://architect.salesforce.com
- W3C. OWL 2 Web Ontology Language. https://www.w3.org/TR/owl2-overview/
- W3C. RDF 1.1 Concepts and Abstract Syntax. https://www.w3.org/TR/rdf11-concepts/