Most Data Contract Tools Don't Enforce Contracts: Here's What Does
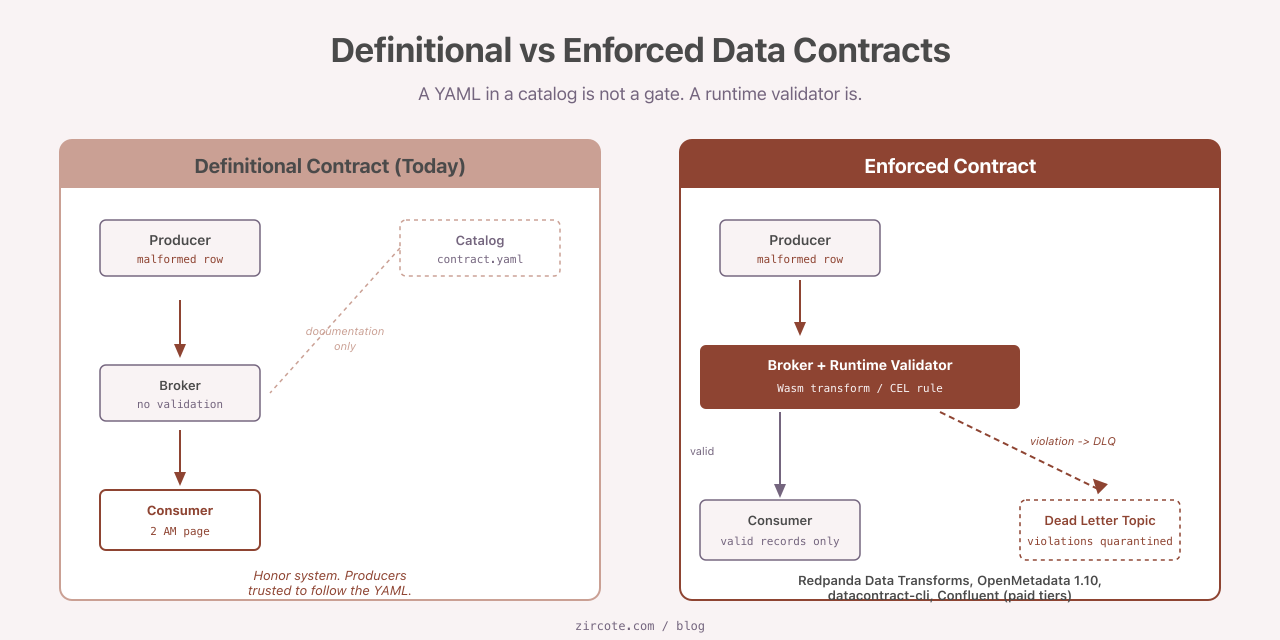
Your team adopted data contracts. You wrote ODCS YAML, attached SLAs, registered the contract in your catalog, and called the governance program live. Now answer one question honestly: when a producer publishes a row that violates the contract, what stops it?
For most teams running the popular open-source stack today, nothing does. The contract sits in a catalog as documentation. The catalog has no opinion about the data flowing past it. Producers ship whatever they ship. Consumers find out at 2 AM when a dashboard breaks.
This is the gap between definitional contracts and runtime-enforced contracts. It is wider than the marketing suggests, and it is the most important question to ask before committing to any data contract platform.
The Specifications Stabilized in 2025
The encouraging news first. The specification fight is over. The Open Data Contract Standard (ODCS) v3.1.0 shipped in December 2025 under the Linux Foundation’s Bitol project, with stricter JSON Schema validation and an official application/odcs+yaml;version=3.1.0 media type (Bitol). The competing Data Contract Specification was deprecated in the same window. Catalogs added native support. Tooling consolidated.
So if you write contracts in 2026, you write them in ODCS. That part is settled.
What is not settled is what to do with the file once you have written it.
DataHub Ships Contracts You Have to Enforce Yourself
DataHub is one of the two dominant open-source data catalogs. The OSS build supports data contract objects: schema assertions, freshness rules, data quality rules, all attached at the data product level. You can write them in the UI, generate them from ODCS, and publish them as governance artifacts.
What the OSS build does not do is run them.
The DataHub documentation is direct about this. Open-source DataHub ships the contract objects. To execute the assertions inside those contracts, you wire in an external runner: a custom scheduler, a third-party DQ tool, or the closed-source DataHub Cloud Data Contract Operator. Results are then published back to DataHub for visualization (DataHub docs).
This is a defensible engineering choice. Catalog as governance registry, runner as separate concern. But it has a failure mode that I see constantly in practice: teams treat publication of a DataHub contract as the end state of their governance work. They have not enforced anything. They have only declared an intention to enforce.
If you ship DataHub OSS without an assertion runner attached, you have built an honor system with a search interface.
Confluent Schema Registry’s Real Enforcement Lives Behind a Paywall
Move down the stack to streaming. If you operate Kafka, the standard answer to “where do I enforce contracts” is the Schema Registry. Confluent’s Schema Registry supports data contracts with Google CEL expressions for validation, field-level transforms via CEL_FIELD, and dead-letter queue routing on rule failure. The CEL library covers most PII validators you would write by hand: isEmail, isUuid, isIpv4, and friends (Confluent docs, Confluent blog on PII).
That is the good half. The other half is the licensing.
Client-side enforcement runs in the producer SDK on the community license. A producer using the official client library validates against the contract before publishing. This catches the message before it lands. It also depends on the producer using the SDK. Anything that bypasses the client library, or uses a stale version, or speaks the Kafka wire protocol directly, sidesteps the entire enforcement chain.
Broker-side Schema ID Validation is the backstop that closes the bypass. The broker rejects any message whose schema does not match what the registry expects, regardless of how the producer behaved. On Confluent Platform this requires an Enterprise license. On Confluent Cloud it is restricted to Dedicated cluster tiers. Basic, Standard, and the confusingly named Enterprise tier on Cloud do not get it (Confluent Platform schema validation, Cloud broker-side validation).
So if you run community Schema Registry, you have client-side enforcement only, and you have to trust every producer in your organization to use a current SDK. For a mature multi-team Kafka deployment, that is not enforcement. It is a courtesy.
Redpanda Quietly Closed the OSS Broker Gap
Here is the finding I have not seen properly absorbed by Kafka practitioners yet.
Redpanda Data Transforms run inline in the broker on the Wasmtime WebAssembly engine. A transform function inspects every message as it passes through the broker, validates it against your schema, routes valid messages to the primary topic, and emits invalid ones to a dead-letter topic. The transform runs broker-side, in process, at line rate (Redpanda docs, Redpanda blog).
This is genuine broker-side contract enforcement, in open source, with no commercial license required. It is the feature Confluent gates behind Enterprise.
The honest tradeoffs: Redpanda is Kafka-protocol-compatible but not 100% behavior-compatible. Some operational tooling and edge-case client paths differ. For brownfield Kafka migrations the porting work is non-trivial. For greenfield streaming workloads where the requirement is “messages that violate the contract must not reach downstream consumers, period,” Redpanda is currently the only production-grade open-source answer.
If your governance program needs broker-side enforcement and your finance team needs a free tier, this is the conversation worth having.
OpenMetadata Became the First OSS Catalog That Actually Runs Contracts
Catalogs treated contracts as registries for years. Storage, not execution. OpenMetadata broke that pattern in version 1.9 (August 2025), which shipped data contracts with schema validations and semantic rules executed on a daily schedule. Version 1.10 (October 2025) added SLA, Terms of Service, and Security spec objects, and full ODCS 3.1 import and export (OpenMetadata 1.10 announcement, contracts docs).
This is a different architectural posture. The catalog is not just where contracts live. It is the engine that runs them.
For a team that wants one open-source system for contract definition, scheduled validation, and SLA reporting, OpenMetadata is currently the only option that does not require a paid tier or a separate orchestration layer. DataHub Cloud is the closest commercial equivalent. Collibra is rolling out contract APIs but not scheduled execution. The OSS gap on the catalog side is real, and OpenMetadata is the project that closed it first.
The Universal Bridge Is datacontract-cli
What if your stack is already committed to dbt, SodaCL, Great Expectations, or specific schema formats like Avro and Protobuf? You do not want to migrate everything to OpenMetadata or rebuild your DQ pipeline on Redpanda.
This is what datacontract-cli solves. A single ODCS contract file exports to dbt model and source YAML, SodaCL checks, Great Expectations suites, Avro and Protobuf schemas, JSON Schema, SQL DDL, and Terraform (datacontract-cli, changelog). The datacontract ci command emits GitHub Actions annotations and Azure DevOps step summaries, which means a contract violation surfaces as a pull request annotation rather than a Slack message someone might miss.
datacontract-cli is not the enforcement engine. It is the translation layer that turns one ODCS file into the enforcement artifact your existing engine already understands. For teams that have already invested in dbt tests or SodaCL checks, this is the most pragmatic on-ramp to ODCS without ripping anything out.
For Protobuf-heavy stacks, the parallel project is Buf, whose breaking-change detection and BSR enforcement model is the cleanest contract enforcement story in the schema-language space (Buf BSR checks, breaking changes).
What to Actually Do
Strip out the marketing and the OSS enforcement landscape in April 2026 sorts into three layers.
Shift-left enforcement at registration time. datacontract-cli for ODCS, buf for Protobuf. Both are fully open source, both run in CI, both block violations before they reach a runtime system. This is the most mature layer and the cheapest to adopt.
Streaming enforcement at runtime. Redpanda Data Transforms if you can run on Redpanda. Confluent Schema Registry on a paid tier if you must run on Confluent. There is no free tier with Kafka-native broker-side enforcement. Pretending there is gets people fired during incidents.
Catalog-scheduled enforcement after ingestion. OpenMetadata 1.10 or later. DataHub requires a commercial add-on. This layer is for batch and warehouse workloads where the cost of detecting a violation hours after ingestion is acceptable.
A team that cannot commit to commercial tooling has a clear path: write contracts in ODCS, enforce at the CI gate via datacontract ci and exports to your DQ engine, evaluate OpenMetadata for catalog-layer scheduled validation, and benchmark Redpanda if Kafka broker-side enforcement is non-negotiable.
What to stop doing: treating DataHub OSS contract publication as enforcement. It is not. Treating community Confluent Schema Registry as a runtime enforcement gate. It is not, not at the broker. Treating ODCS adoption as a governance victory. The file is only as enforced as the system reading it.
The next time someone on your team announces that contracts are live, ask which of these three layers is doing the enforcing. If the answer is “the catalog has the YAML,” the work is not done. It has not started.
Sources
- Bitol Announces ODCS v3.1.0
- Data Contract Specification (deprecated)
- DataHub Data Contract documentation
- Confluent Schema Registry Data Contracts
- Confluent Platform Schema Validation
- Confluent Cloud Broker-Side Schema Validation
- Confluent: How to Protect PII in Kafka
- Redpanda Data Transforms documentation
- Redpanda Wasm Architecture
- OpenMetadata 1.10 Announcement
- OpenMetadata Data Contracts Guide
- datacontract-cli on GitHub
- datacontract-cli changelog
- Buf BSR Checks
- Buf Breaking Change Detection